Sentry部署
私有化部署-快速部署-测试验证
依赖
docker-compose
docker compose up
私有化部署-集群部署
仓库地址
注: 非官方提供,官方只提供了Docker-compose的部署方式
基础组件(新版)
修改Helm-chart
sentry/templates/snuba/_helper-snuba.tpl
以下是 Sentry Snuba 中这些 storage_sets 的用途分类和详细说明,按功能模块整理:
核心功能
| Storage Set | 用途 | 对应数据表 | 分片键建议 |
|---|---|---|---|
| events | 存储所有错误事件(Error Events),是 Sentry 的核心数据表。 | events_local | sipHash64(event_id) |
| transactions | 存储性能监控的 Transaction 事件(APM 数据)。 | transactions_local | sipHash64(event_id) |
| sessions | 存储会话健康度数据(Release Health),用于统计版本崩溃率和用户留存。 | sessions_local | sipHash64(session_id) |
| profiles | 存储性能剖析数据(Profiling),用于代码级性能分析。 | profiles_local | sipHash64(profile_id) |
| replays | 存储用户行为回放数据(Session Replay),记录用户操作轨迹。 | replays_local | sipHash64(replay_id) |
指标与监控
| Storage Set | 用途 | 对应数据表 | 分片键建议 |
|---|---|---|---|
| metrics | 存储自定义指标和系统指标(旧版指标系统)。 | metrics_local | sipHash64(project_id) |
| generic_metrics_sets | 存储 Set 类型指标(如唯一用户数),属于通用指标系统(新版)。 | generic_metrics_sets_local | sipHash64(project_id) |
| generic_metrics_distributions | 存储分布类型指标(如延迟百分位数),属于通用指标系统。 | generic_metrics_distributions_local | sipHash64(project_id) |
| generic_metrics_counters | 存储计数器类型指标(如请求次数),属于通用指标系统。 | generic_metrics_counters_local | sipHash64(project_id) |
| generic_metrics_gauges | 存储瞬时值指标(如当前内存使用量),属于通用指标系统。 | generic_metrics_gauges_local | sipHash64(project_id) |
| metrics_summaries | 存储指标的聚合摘要(实验性功能)。 | metrics_summaries_local | rand() |
调试与诊断
| Storage Set | 用途 | 对应数据表 | 分片键建议 |
|---|---|---|---|
| spans | 存储分布式追踪的 Span 数据(APM 链路追踪)。 | spans_local | sipHash64(trace_id) |
| functions | 存储函数级性能剖析数据(如代码热点函数)。 | functions_local | sipHash64(profile_id) |
| profile_chunks | 存储性能剖析的原始数据块(用于 Profiling 的详细分析)。 | profile_chunks_local | sipHash64(profile_id) |
系统与运维
| Storage Set | 用途 | 对应数据表 | 分片键建议 |
|---|---|---|---|
| outcomes | 存储事件处理结果(如丢弃、限流、成功),用于监控 Sentry 自身的处理状态。 | outcomes_local | rand() |
| querylog | 记录 Snuba 的查询日志,用于审计和分析查询性能。 | querylog_local | rand() |
| migrations | 存储 Snuba 的数据库迁移记录(内部管理用)。 | 无独立表,管理元数据 | 无需分片 |
高级功能
| Storage Set | 用途 | 对应数据表 | 分片键建议 |
|---|---|---|---|
| cdc | Change Data Capture 数据变更捕获(用于实时数据管道,如 Kafka 同步)。 | cdc_local | sipHash64(message_id) |
| discover | 支持 Discover 查询的衍生数据集(基于 events 和 transactions 的聚合视图)。 | 无独立表,逻辑视图 | 无需分片 |
| events_ro | 只读副本的 Events 表(用于分流查询负载)。 | events_ro_local | 同 events |
| search_issues | 支持全文搜索的事件索引(实验性功能)。 | search_issues_local | sipHash64(event_id) |
| group_attributes | 存储 Issue 的扩展属性(如标签、优先级)。 | group_attributes_local | sipHash64(group_id) |
| events_analytics_platform | 企业级事件分析平台数据(高级分析功能)。 | events_analytics_platform_local | sipHash64(event_id) |
sentry/value.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
900
901
902
903
904
905
906
907
908
909
910
911
912
913
914
915
916
917
918
919
920
921
922
923
924
925
926
927
928
929
930
931
932
933
934
935
936
937
938
939
940
941
942
943
944
945
946
947
948
949
950
951
952
953
954
955
956
957
958
959
960
961
962
963
964
965
966
967
968
969
970
971
972
973
974
975
976
977
978
979
980
981
982
983
984
985
986
987
988
989
990
991
992
993
994
995
996
997
998
999
1000
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
1011
1012
1013
1014
1015
1016
1017
1018
1019
1020
1021
1022
1023
1024
1025
1026
1027
1028
1029
1030
1031
1032
1033
1034
1035
1036
1037
1038
1039
1040
1041
1042
1043
1044
1045
1046
1047
1048
1049
1050
1051
1052
1053
1054
1055
1056
1057
1058
1059
1060
1061
1062
1063
1064
1065
1066
1067
1068
1069
1070
1071
1072
1073
1074
1075
1076
1077
1078
1079
1080
1081
1082
1083
1084
1085
1086
1087
1088
1089
1090
1091
1092
1093
1094
1095
1096
1097
1098
1099
1100
1101
1102
1103
1104
1105
1106
1107
1108
1109
1110
1111
1112
1113
1114
1115
1116
1117
1118
1119
1120
1121
1122
1123
1124
1125
1126
1127
1128
1129
1130
1131
1132
1133
1134
1135
1136
1137
1138
1139
1140
1141
1142
1143
1144
1145
1146
1147
1148
1149
1150
1151
1152
1153
1154
1155
1156
1157
1158
1159
1160
1161
1162
1163
1164
1165
1166
1167
1168
1169
1170
1171
1172
1173
1174
1175
1176
1177
1178
1179
1180
1181
1182
1183
1184
1185
1186
1187
1188
1189
1190
1191
1192
1193
1194
1195
1196
1197
1198
1199
1200
1201
1202
1203
1204
1205
1206
1207
1208
1209
1210
1211
1212
1213
1214
1215
1216
1217
1218
1219
1220
1221
1222
1223
1224
1225
1226
1227
1228
1229
1230
1231
1232
1233
1234
1235
1236
1237
1238
1239
1240
1241
1242
1243
1244
1245
1246
1247
1248
1249
1250
1251
1252
1253
1254
1255
1256
1257
1258
1259
1260
1261
1262
1263
1264
1265
1266
1267
1268
1269
1270
1271
1272
1273
1274
1275
1276
1277
1278
1279
1280
1281
1282
1283
1284
1285
1286
1287
1288
1289
1290
1291
1292
1293
1294
1295
1296
1297
1298
1299
1300
1301
1302
1303
1304
1305
1306
1307
1308
1309
1310
1311
1312
1313
1314
1315
1316
1317
1318
1319
1320
1321
1322
1323
1324
1325
1326
1327
1328
1329
1330
1331
1332
1333
1334
1335
1336
1337
1338
1339
1340
1341
1342
1343
1344
1345
1346
1347
1348
1349
1350
1351
1352
1353
1354
1355
1356
1357
1358
1359
1360
1361
1362
1363
1364
1365
1366
1367
1368
1369
1370
1371
1372
1373
1374
1375
1376
1377
1378
1379
1380
1381
1382
1383
1384
1385
1386
1387
1388
1389
1390
1391
1392
1393
1394
1395
1396
1397
1398
1399
1400
1401
1402
1403
1404
1405
1406
1407
1408
1409
1410
1411
1412
1413
1414
1415
1416
1417
1418
1419
1420
1421
1422
1423
1424
1425
1426
1427
1428
1429
1430
1431
1432
1433
1434
1435
1436
1437
1438
1439
1440
1441
1442
1443
1444
1445
1446
1447
1448
1449
1450
1451
1452
1453
1454
1455
1456
1457
1458
1459
1460
1461
1462
1463
1464
1465
1466
1467
1468
1469
1470
1471
1472
1473
1474
1475
1476
1477
1478
1479
1480
1481
1482
1483
1484
1485
1486
1487
1488
1489
1490
1491
1492
1493
1494
1495
1496
1497
1498
1499
1500
1501
1502
1503
1504
1505
1506
1507
1508
1509
1510
1511
1512
1513
1514
1515
1516
1517
1518
1519
1520
1521
1522
1523
1524
1525
1526
1527
1528
1529
1530
1531
1532
1533
1534
1535
1536
1537
1538
1539
1540
1541
1542
1543
1544
1545
1546
1547
1548
1549
1550
1551
1552
1553
1554
1555
1556
1557
1558
1559
1560
1561
1562
1563
1564
1565
1566
1567
1568
1569
1570
1571
1572
1573
1574
1575
1576
1577
1578
1579
1580
1581
1582
1583
1584
1585
1586
1587
1588
1589
1590
1591
1592
1593
1594
1595
1596
1597
1598
1599
1600
1601
1602
1603
1604
1605
1606
1607
1608
1609
1610
1611
1612
1613
1614
1615
1616
1617
1618
1619
1620
1621
1622
1623
1624
1625
1626
1627
1628
1629
1630
1631
1632
1633
1634
1635
1636
1637
1638
1639
1640
1641
1642
1643
1644
1645
1646
1647
1648
1649
1650
1651
1652
1653
1654
1655
1656
1657
1658
1659
1660
1661
1662
1663
1664
1665
1666
1667
1668
1669
1670
1671
1672
1673
1674
1675
1676
1677
1678
1679
1680
1681
1682
1683
1684
1685
1686
1687
1688
1689
1690
1691
1692
1693
1694
1695
1696
1697
1698
1699
1700
1701
1702
1703
1704
1705
1706
1707
1708
1709
1710
1711
1712
1713
1714
1715
1716
1717
1718
1719
1720
1721
1722
1723
1724
1725
1726
1727
1728
1729
1730
1731
1732
1733
1734
1735
1736
1737
1738
1739
1740
1741
1742
1743
1744
1745
1746
1747
1748
1749
1750
1751
1752
1753
1754
1755
1756
1757
1758
1759
1760
1761
1762
1763
1764
1765
1766
1767
1768
1769
1770
1771
1772
1773
1774
1775
1776
1777
1778
1779
1780
1781
1782
1783
1784
1785
1786
1787
1788
1789
1790
1791
1792
1793
1794
1795
1796
1797
1798
1799
1800
1801
1802
1803
1804
1805
1806
1807
1808
1809
1810
1811
1812
1813
1814
1815
1816
1817
1818
1819
1820
1821
1822
1823
1824
1825
1826
1827
1828
1829
1830
1831
1832
1833
1834
1835
1836
1837
1838
1839
1840
1841
1842
1843
1844
1845
1846
1847
1848
1849
1850
1851
1852
1853
1854
1855
1856
1857
1858
1859
1860
1861
1862
1863
1864
1865
1866
1867
1868
1869
1870
1871
1872
1873
1874
1875
1876
1877
1878
1879
1880
1881
1882
1883
1884
1885
1886
1887
1888
1889
1890
1891
1892
1893
1894
1895
1896
1897
1898
1899
1900
1901
1902
1903
1904
1905
1906
1907
1908
1909
1910
1911
1912
1913
1914
1915
1916
1917
1918
1919
1920
1921
1922
1923
1924
1925
1926
1927
1928
1929
1930
1931
1932
1933
1934
1935
1936
1937
1938
1939
1940
1941
1942
1943
1944
1945
1946
1947
1948
1949
1950
1951
1952
1953
1954
1955
1956
1957
1958
1959
1960
1961
1962
1963
1964
1965
1966
1967
1968
1969
1970
1971
1972
1973
1974
1975
1976
1977
1978
1979
1980
1981
1982
1983
1984
1985
1986
1987
1988
1989
1990
1991
1992
1993
1994
1995
1996
1997
1998
1999
2000
2001
2002
2003
2004
2005
2006
2007
2008
2009
2010
2011
2012
2013
2014
2015
2016
2017
2018
2019
2020
2021
2022
2023
2024
2025
2026
2027
2028
2029
2030
2031
2032
2033
2034
2035
2036
2037
2038
2039
2040
2041
2042
2043
2044
2045
2046
2047
2048
2049
2050
2051
2052
2053
2054
2055
2056
2057
2058
2059
2060
2061
2062
2063
2064
2065
2066
2067
2068
2069
2070
2071
2072
2073
2074
2075
2076
2077
2078
2079
2080
2081
2082
2083
2084
2085
2086
2087
2088
2089
2090
2091
2092
2093
2094
2095
2096
2097
2098
2099
2100
2101
2102
2103
2104
2105
2106
2107
2108
2109
2110
2111
2112
2113
2114
2115
2116
2117
2118
2119
2120
2121
2122
2123
2124
2125
2126
2127
2128
2129
2130
2131
2132
2133
2134
2135
2136
2137
2138
2139
2140
2141
2142
2143
2144
2145
2146
2147
2148
2149
2150
2151
2152
2153
2154
2155
2156
2157
2158
2159
2160
2161
2162
2163
2164
2165
2166
2167
2168
2169
2170
2171
2172
2173
2174
2175
2176
2177
2178
2179
2180
2181
2182
2183
2184
2185
2186
2187
2188
2189
2190
2191
2192
2193
2194
2195
2196
2197
2198
2199
2200
2201
2202
2203
2204
2205
2206
2207
2208
2209
2210
2211
2212
2213
2214
2215
2216
2217
2218
2219
2220
2221
2222
2223
2224
2225
2226
2227
2228
2229
2230
2231
2232
2233
2234
2235
2236
2237
2238
2239
2240
2241
2242
2243
2244
2245
2246
2247
2248
2249
2250
2251
2252
2253
2254
2255
2256
2257
2258
2259
2260
2261
2262
2263
2264
2265
2266
2267
2268
2269
2270
2271
2272
2273
2274
2275
2276
2277
2278
2279
2280
2281
2282
2283
2284
2285
2286
2287
2288
2289
2290
2291
2292
2293
2294
2295
2296
2297
2298
2299
2300
2301
2302
2303
2304
2305
2306
2307
2308
2309
2310
2311
2312
2313
2314
2315
2316
2317
2318
2319
2320
2321
2322
2323
2324
2325
2326
2327
2328
2329
2330
2331
2332
2333
2334
2335
2336
2337
2338
2339
2340
2341
2342
2343
2344
2345
2346
2347
2348
2349
2350
2351
2352
2353
2354
2355
2356
2357
2358
2359
2360
2361
2362
2363
2364
2365
2366
2367
2368
2369
2370
2371
2372
2373
2374
2375
2376
2377
2378
2379
2380
2381
2382
2383
2384
2385
2386
2387
2388
2389
2390
2391
2392
2393
2394
2395
2396
2397
2398
2399
2400
2401
2402
2403
2404
2405
2406
2407
2408
2409
2410
2411
2412
2413
2414
2415
2416
2417
2418
2419
2420
2421
2422
2423
2424
2425
2426
2427
2428
2429
2430
2431
2432
2433
2434
2435
2436
2437
2438
2439
2440
2441
2442
2443
2444
2445
2446
2447
2448
2449
2450
2451
2452
2453
2454
2455
2456
2457
2458
2459
2460
2461
2462
2463
2464
2465
2466
2467
2468
2469
2470
2471
2472
2473
2474
2475
2476
2477
2478
2479
2480
2481
2482
2483
2484
2485
2486
2487
2488
2489
2490
2491
2492
2493
2494
2495
2496
2497
2498
2499
2500
2501
2502
2503
2504
2505
2506
2507
2508
2509
2510
2511
2512
2513
2514
2515
2516
2517
2518
2519
2520
2521
2522
2523
2524
2525
2526
2527
2528
2529
2530
2531
2532
2533
2534
2535
2536
2537
2538
2539
2540
2541
2542
2543
2544
2545
2546
2547
2548
2549
2550
2551
2552
2553
2554
2555
2556
2557
2558
2559
2560
2561
2562
2563
2564
2565
2566
2567
2568
2569
2570
2571
2572
2573
2574
2575
2576
2577
2578
2579
2580
2581
2582
2583
2584
2585
2586
2587
2588
2589
2590
2591
2592
2593
2594
2595
2596
2597
2598
2599
2600
2601
2602
2603
2604
2605
2606
2607
2608
2609
2610
2611
2612
2613
2614
2615
2616
2617
2618
2619
2620
2621
2622
2623
2624
2625
2626
2627
2628
2629
2630
2631
2632
2633
2634
2635
2636
2637
2638
2639
2640
2641
2642
2643
2644
2645
2646
2647
2648
2649
2650
2651
2652
2653
2654
2655
2656
2657
2658
2659
2660
2661
2662
2663
2664
2665
2666
2667
2668
2669
2670
2671
2672
2673
2674
2675
2676
2677
2678
2679
2680
2681
2682
2683
2684
2685
2686
2687
2688
2689
2690
2691
2692
2693
2694
2695
2696
2697
2698
2699
2700
2701
2702
2703
2704
2705
2706
2707
2708
2709
2710
2711
2712
2713
2714
2715
2716
2717
2718
2719
2720
2721
2722
2723
2724
2725
2726
2727
2728
2729
2730
2731
2732
2733
2734
2735
2736
2737
2738
2739
2740
2741
2742
2743
2744
2745
2746
2747
2748
2749
2750
2751
2752
2753
2754
2755
2756
2757
2758
2759
2760
2761
2762
2763
2764
2765
2766
2767
2768
2769
2770
2771
2772
2773
2774
2775
2776
2777
2778
2779
2780
2781
2782
2783
2784
2785
2786
2787
2788
2789
2790
2791
2792
2793
2794
2795
2796
2797
2798
2799
2800
2801
2802
2803
2804
2805
2806
2807
2808
2809
prefix:
# Set this to true to support IPV6 networks
ipv6: false
global:
# Set SAMPLED_DEFAULT_RATE parameter for all projects
# sampledDefaultRate: 1.0
nodeSelector: {}
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
tolerations:
- key: "serv.type"
operator: "Equal"
value: "md"
effect: "NoSchedule"
sidecars: []
volumes: []
user:
create: true
email: sentry.notify@hannto.com
password: ******
## set this value to an existingSecret name to create the admin user with the password in the secret
# existingSecret: sentry-admin-password
## set this value to an existingSecretKey which holds the password to be used for sentry admin user default key is `admin-password`
# existingSecretKey: admin-password
# this is required on the first installation, as sentry has to be initialized first
# recommended to set false for updating the helm chart afterwards,
# as you will have some downtime on each update if it's a hook
# deploys relay & snuba consumers as post hooks
asHook: true
images:
sentry:
repository: hub.kce.ksyun.com/middleware/sentry
#tag: Chart.AppVersion
tag: 25.3.0
pullPolicy: IfNotPresent
imagePullSecrets:
- name: ksyunregistrykey
snuba:
repository: hub.kce.ksyun.com/middleware/snuba
tag: 25.2.0
pullPolicy: IfNotPresent
imagePullSecrets:
- name: ksyunregistrykey
relay:
repository: hub.kce.ksyun.com/middleware/relay
tag: 25.2.0
pullPolicy: IfNotPresent
imagePullSecrets:
- name: ksyunregistrykey
symbolicator:
# repository: getsentry/symbolicator
# tag: Chart.AppVersion
# pullPolicy: IfNotPresent
imagePullSecrets: []
vroom:
# repository: getsentry/vroom
# tag: Chart.AppVersion
# pullPolicy: IfNotPresent
imagePullSecrets: []
serviceAccount:
# serviceAccount.annotations -- Additional Service Account annotations.
annotations: {}
# serviceAccount.enabled -- If `true`, a custom Service Account will be used.
enabled: false
# serviceAccount.name -- The base name of the ServiceAccount to use. Will be appended with e.g. `snuba-api` or `web` for the pods accordingly.
name: "sentry"
# serviceAccount.automountServiceAccountToken -- Automount API credentials for a Service Account.
automountServiceAccountToken: true
vroom:
# annotations: {}
# args: []
replicas: 1
env: []
probeFailureThreshold: 5
probeInitialDelaySeconds: 10
probePeriodSeconds: 10
probeSuccessThreshold: 1
probeTimeoutSeconds: 2
resources: {}
# requests:
# cpu: 100m
# memory: 700Mi
affinity: {}
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# priorityClassName: ""
service:
annotations: {}
# tolerations: []
# podLabels: {}
autoscaling:
enabled: false
minReplicas: 2
maxReplicas: 5
targetCPUUtilizationPercentage: 50
sidecars: []
# topologySpreadConstraints: []
volumes: []
volumeMounts: []
relay:
enabled: true
# annotations: {}
replicas: 1
# args: []
mode: managed
env: []
probeFailureThreshold: 5
probeInitialDelaySeconds: 10
probePeriodSeconds: 10
probeSuccessThreshold: 1
probeTimeoutSeconds: 2
resources: {}
# requests:
# cpu: 100m
# memory: 700Mi
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
nodeSelector: {}
# healthCheck:
# readinessRequestPath: ""
securityContext: {}
# if you are using GKE Ingress controller use 'securityPolicy' to add Google Cloud Armor Ingress policy
securityPolicy: ""
# if you are using GKE Ingress controller use 'customResponseHeaders' to add custom response header
customResponseHeaders: []
containerSecurityContext: {}
service:
annotations: {}
# tolerations: []
# podLabels: {}
# priorityClassName: ""
autoscaling:
enabled: true
minReplicas: 2
maxReplicas: 5
targetCPUUtilizationPercentage: 50
sidecars: []
topologySpreadConstraints: []
volumes: []
volumeMounts: []
init:
resources: {}
# additionalArgs: []
# credentialsSubcommand: ""
# env: []
# volumes: []
# volumeMounts: []
# cache:
# envelopeBufferSize: 1000
# logging:
# level: info
# format: json
processing:
kafkaConfig:
messageMaxBytes: 50000000
# messageTimeoutMs:
# requestTimeoutMs:
# deliveryTimeoutMs:
# apiVersionRequestTimeoutMs:
# additionalKafkaConfig:
# - name: compression.type
# value: "lz4"
# Override custom Kafka topic names
# WARNING: If you update this and you are also using the Kafka subchart, you need to update the provisioned Topic names in this values as well!
# kafkaTopicOverrides:
# prefix: ""
# enable and reference the volume
geodata:
accountID: ""
licenseKey: ""
editionIDs: ""
persistence:
## If defined, storageClassName: <storageClass>
## If undefined (the default) or set to null, no storageClassName spec is
## set, choosing the default provisioner. (gp2 on AWS, standard on
## GKE, AWS & OpenStack)
storageClass: "ksc-kfs" # for example: csi-s3
size: 1Gi
volumeName: "" # for example: data-sentry-geoip
# mountPath of the volume containing the database
mountPath: "" # for example: /usr/share/GeoIP
# path to the geoip database inside the volumemount
path: "" # for example: /usr/share/GeoIP/GeoLite2-City.mmdb
sentry:
# to not generate a sentry-secret, use these 2 values to reference an existing secret
# existingSecret: "my-secret"
# existingSecretKey: "my-secret-key"
singleOrganization: true
web:
enabled: true
# if using filestore backend filesystem with RWO access, set strategyType to Recreate
strategyType: RollingUpdate
replicas: 3
env: []
existingSecretEnv: ""
probeFailureThreshold: 5
probeInitialDelaySeconds: 10
probePeriodSeconds: 10
probeSuccessThreshold: 1
probeTimeoutSeconds: 2
resources: {}
# requests:
# cpu: 200m
# memory: 850Mi
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
nodeSelector: {}
securityContext: {}
# if you are using GKE Ingress controller use 'securityPolicy' to add Google Cloud Armor Ingress policy
securityPolicy: ""
# if you are using GKE Ingress controller use 'customResponseHeaders' to add custom response header
customResponseHeaders: []
containerSecurityContext: {}
service:
annotations: {}
# tolerations: []
# podLabels: {}
# Mount and use custom CA
# customCA:
# secretName: custom-ca
# item: ca.crt
logLevel: "WARNING" # DEBUG|INFO|WARNING|ERROR|CRITICAL|FATAL
logFormat: "human" # human|machine
autoscaling:
enabled: true
minReplicas: 3
maxReplicas: 5
targetCPUUtilizationPercentage: 50
sidecars: []
topologySpreadConstraints: []
volumes: []
volumeMounts: []
# workers: 3
features:
orgSubdomains: false
vstsLimitedScopes: true
enableProfiling: false
enableSessionReplay: true
enableFeedback: false
enableSpan: false
# example customFeature to enable Metrics(beta) https://docs.sentry.io/product/metrics/
# customFeatures:
# - organizations:custom-metric
# - organizations:custom-metrics-experimental
# - organizations:derive-code-mappings
# other feature here https://github.com/getsentry/sentry/blob/24.11.2/src/sentry/features/temporary.py
worker:
enabled: true
# annotations: {}
replicas: 3
# concurrency: 4
env: []
existingSecretEnv: ""
resources: {}
# requests:
# cpu: 1000m
# memory: 1100Mi
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
nodeSelector: {}
# tolerations: []
# podLabels: {}
logLevel: "WARNING" # DEBUG|INFO|WARNING|ERROR|CRITICAL|FATAL
logFormat: "human" # human|machine
# excludeQueues: ""
# maxTasksPerChild: 1000
# it's better to use prometheus adapter and scale based on
# the size of the rabbitmq queue
autoscaling:
enabled: true
minReplicas: 3
maxReplicas: 5
targetCPUUtilizationPercentage: 50
livenessProbe:
enabled: true
periodSeconds: 60
timeoutSeconds: 10
failureThreshold: 3
sidecars: []
# securityContext: {}
# containerSecurityContext: {}
# priorityClassName: ""
topologySpreadConstraints: []
volumes: []
volumeMounts: []
# allows to dedicate some workers to specific queues
workerEvents:
## If the number of exceptions increases, it is recommended to enable workerEvents
enabled: false
# annotations: {}
queues: "events.save_event,post_process_errors"
## When increasing the number of exceptions and enabling workerEvents, it is recommended to increase the number of their replicas
replicas: 1
# concurrency: 4
env: []
resources: {}
affinity: {}
nodeSelector: {}
# tolerations: []
# podLabels: {}
# logLevel: "WARNING" # DEBUG|INFO|WARNING|ERROR|CRITICAL|FATAL
# logFormat: "machine" # human|machine
# maxTasksPerChild: 1000
# it's better to use prometheus adapter and scale based on
# the size of the rabbitmq queue
autoscaling:
enabled: false
minReplicas: 2
maxReplicas: 5
targetCPUUtilizationPercentage: 50
livenessProbe:
enabled: false
periodSeconds: 60
timeoutSeconds: 10
failureThreshold: 3
sidecars: []
# securityContext: {}
# containerSecurityContext: {}
# priorityClassName: ""
topologySpreadConstraints: []
volumes: []
volumeMounts: []
# allows to dedicate some workers to specific queues
workerTransactions:
enabled: false
# annotations: {}
queues: "events.save_event_transaction,post_process_transactions"
replicas: 1
# concurrency: 4
env: []
resources: {}
affinity: {}
nodeSelector: {}
# tolerations: []
# podLabels: {}
# logLevel: "WARNING" # DEBUG|INFO|WARNING|ERROR|CRITICAL|FATAL
# logFormat: "machine" # human|machine
# maxTasksPerChild: 1000
# it's better to use prometheus adapter and scale based on
# the size of the rabbitmq queue
autoscaling:
enabled: false
minReplicas: 2
maxReplicas: 5
targetCPUUtilizationPercentage: 50
livenessProbe:
enabled: false
periodSeconds: 60
timeoutSeconds: 10
failureThreshold: 3
sidecars: []
# securityContext: {}
# containerSecurityContext: {}
# priorityClassName: ""
topologySpreadConstraints: []
volumes: []
volumeMounts: []
ingestConsumerAttachments:
enabled: true
replicas: 1
# concurrency: 4
# maxBatchTimeMs: 20000
# maxPollIntervalMs: 30000
env: []
resources: {}
# requests:
# cpu: 200m
# memory: 700Mi
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# maxBatchSize: ""
# logLevel: info
# it's better to use prometheus adapter and scale based on
# the size of the rabbitmq queue
autoscaling:
enabled: true
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 50
sidecars: []
topologySpreadConstraints: []
volumes: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
ingestConsumerEvents:
enabled: true
replicas: 1
# concurrency: 4
env: []
resources: {}
# requests:
# cpu: 300m
# memory: 500Mi
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# maxBatchSize: ""
# logLevel: "info"
# inputBlockSize: ""
# maxBatchTimeMs: ""
# it's better to use prometheus adapter and scale based on
# the size of the rabbitmq queue
autoscaling:
enabled: true
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 50
sidecars: []
topologySpreadConstraints: []
volumes: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
ingestConsumerTransactions:
enabled: true
replicas: 1
# concurrency: 4
env: []
resources: {}
# requests:
# cpu: 200m
# memory: 500Mi
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# maxBatchSize: ""
# logLevel: "info"
# inputBlockSize: ""
# maxBatchTimeMs: ""
# it's better to use prometheus adapter and scale based on
# the size of the rabbitmq queue
autoscaling:
enabled: true
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 50
sidecars: []
topologySpreadConstraints: []
volumes: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
ingestReplayRecordings:
enabled: true
replicas: 1
env: []
resources: {}
# requests:
# cpu: 100m
# memory: 250Mi
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# it's better to use prometheus adapter and scale based on
# the size of the rabbitmq queue
autoscaling:
enabled: true
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 50
sidecars: []
topologySpreadConstraints: []
volumes: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
ingestProfiles:
replicas: 1
env: []
resources: {}
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# it's better to use prometheus adapter and scale based on
# the size of the rabbitmq queue
autoscaling:
enabled: true
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 50
sidecars: []
topologySpreadConstraints: []
volumes: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
ingestOccurrences:
enabled: true
replicas: 1
env: []
resources: {}
# requests:
# cpu: 100m
# memory: 250Mi
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# it's better to use prometheus adapter and scale based on
# the size of the rabbitmq queue
autoscaling:
enabled: true
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 50
sidecars: []
topologySpreadConstraints: []
volumes: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
ingestFeedback:
enabled: false
replicas: 1
env: []
resources: {}
# requests:
# cpu: 100m
# memory: 250Mi
affinity: {}
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# it's better to use prometheus adapter and scale based on
# the size of the rabbitmq queue
autoscaling:
enabled: false
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 50
sidecars: []
topologySpreadConstraints: []
volumes: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
ingestMonitors:
enabled: true
replicas: 1
env: []
resources: {}
# requests:
# cpu: 100m
# memory: 250Mi
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# it's better to use prometheus adapter and scale based on
# the size of the rabbitmq queue
autoscaling:
enabled: true
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 50
sidecars: []
topologySpreadConstraints: []
volumes: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
monitorsClockTasks:
enabled: false
replicas: 1
env: []
resources: {}
# requests:
# cpu: 100m
# memory: 250Mi
affinity: {}
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# it's better to use prometheus adapter and scale based on
# the size of the rabbitmq queue
autoscaling:
enabled: false
sidecars: []
topologySpreadConstraints: []
volumes: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
monitorsClockTick:
enabled: false
replicas: 1
env: []
resources: {}
# requests:
# cpu: 100m
# memory: 250Mi
affinity: {}
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# it's better to use prometheus adapter and scale based on
# the size of the rabbitmq queue
autoscaling:
enabled: false
sidecars: []
topologySpreadConstraints: []
volumes: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
billingMetricsConsumer:
enabled: true
replicas: 1
env: []
resources: {}
# requests:
# cpu: 100m
# memory: 250Mi
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# it's better to use prometheus adapter and scale based on
# the size of the rabbitmq queue
autoscaling:
enabled: true
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 50
sidecars: []
topologySpreadConstraints: []
volumes: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
genericMetricsConsumer:
enabled: true
replicas: 1
# concurrency: 4
env: []
resources: {}
# requests:
# cpu: 200m
# memory: 500Mi
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# maxPollIntervalMs: ""
# logLevel: "info"
# it's better to use prometheus adapter and scale based on
# the size of the rabbitmq queue
autoscaling:
enabled: true
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 50
sidecars: []
topologySpreadConstraints: []
volumes: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
metricsConsumer:
enabled: true
replicas: 1
# concurrency: 4
env: []
resources: {}
# requests:
# cpu: 200m
# memory: 500Mi
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# logLevel: "info"
# maxPollIntervalMs: ""
# it's better to use prometheus adapter and scale based on
# the size of the rabbitmq queue
autoscaling:
enabled: false
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 50
sidecars: []
topologySpreadConstraints: []
volumes: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
cron:
enabled: true
replicas: 1
env: []
resources: {}
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
nodeSelector: {}
# tolerations: []
# podLabels: {}
sidecars: []
topologySpreadConstraints: []
volumes: []
# volumeMounts: []
# logLevel: "WARNING" # DEBUG|INFO|WARNING|ERROR|CRITICAL|FATAL
# logFormat: "machine" # human|machine
subscriptionConsumerEvents:
enabled: true
replicas: 1
env: []
resources: {}
# requests:
# cpu: 200m
# memory: 500Mi
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
sidecars: []
topologySpreadConstraints: []
volumes: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
# volumeMounts: []
subscriptionConsumerTransactions:
enabled: true
replicas: 1
env: []
resources: {}
# requests:
# cpu: 200m
# memory: 500Mi
affinity: {}
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
sidecars: []
topologySpreadConstraints: []
volumes: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
# volumeMounts: []
postProcessForwardErrors:
enabled: true
replicas: 1
env: []
resources: {}
# requests:
# cpu: 150m
# memory: 500Mi
affinity: {}
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
sidecars: []
topologySpreadConstraints: []
volumes: []
# volumeMounts: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
postProcessForwardTransactions:
enabled: true
replicas: 1
# processes: 1
env: []
resources: {}
# requests:
# cpu: 200m
# memory: 500Mi
affinity: {}
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
sidecars: []
topologySpreadConstraints: []
volumes: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumeMounts: []
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
postProcessForwardIssuePlatform:
enabled: true
replicas: 1
env: []
resources: {}
# requests:
# cpu: 300m
# memory: 500Mi
affinity: {}
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
sidecars: []
topologySpreadConstraints: []
volumes: []
# volumeMounts: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
subscriptionConsumerGenericMetrics:
enabled: true
replicas: 1
# concurrency: 1
env: []
resources: {}
# requests:
# cpu: 200m
# memory: 500Mi
affinity: {}
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
sidecars: []
topologySpreadConstraints: []
volumes: []
# volumeMounts: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
subscriptionConsumerMetrics:
enabled: true
replicas: 1
# concurrency: 1
env: []
resources: {}
# requests:
# cpu: 200m
# memory: 500Mi
affinity: {}
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
sidecars: []
topologySpreadConstraints: []
volumes: []
# volumeMounts: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
cleanup:
successfulJobsHistoryLimit: 5
failedJobsHistoryLimit: 5
activeDeadlineSeconds: 100
concurrencyPolicy: Allow
concurrency: 1
enabled: true
schedule: "0 0 * * *"
days: 90
# logLevel: INFO
logLevel: ''
# securityContext: {}
# containerSecurityContext: {}
sidecars: []
volumes: []
# volumeMounts: []
serviceAccount: {}
# Sentry settings of connections to Kafka
kafka:
message:
max:
bytes: 50000000
compression:
type: # 'gzip', 'snappy', 'lz4', 'zstd'
socket:
timeout:
ms: 1000
snuba:
api:
enabled: true
replicas: 1
# set command to ["snuba","api"] if securityContext.runAsUser > 0
# see: https://github.com/getsentry/snuba/issues/956
command: []
# - snuba
# - api
env: []
probeInitialDelaySeconds: 10
liveness:
timeoutSeconds: 2
readiness:
timeoutSeconds: 2
resources: {}
# requests:
# cpu: 100m
# memory: 150Mi
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
service:
annotations: {}
# tolerations: []
# podLabels: {}
autoscaling:
enabled: true
minReplicas: 2
maxReplicas: 5
targetCPUUtilizationPercentage: 50
sidecars: []
topologySpreadConstraints: []
volumes: []
# volumeMounts: []
consumer:
enabled: true
replicas: 1
env: []
resources: {}
affinity: {}
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# autoOffsetReset: "earliest"
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# noStrictOffsetReset: false
# maxBatchSize: ""
# processes: ""
# inputBlockSize: ""
# outputBlockSize: ""
maxBatchTimeMs: 750
# queuedMaxMessagesKbytes: ""
# queuedMinMessages: ""
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# volumes:
# - name: dshm
# emptyDir:
# medium: Memory
outcomesConsumer:
enabled: true
replicas: 1
env: []
resources: {}
affinity: {}
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
maxBatchSize: "3"
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# processes: ""
# inputBlockSize: ""
# outputBlockSize: ""
# maxBatchTimeMs: ""
# queuedMaxMessagesKbytes: ""
# queuedMinMessages: ""
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# volumes:
# - name: dshm
# emptyDir:
# medium: Memory
outcomesBillingConsumer:
enabled: true
replicas: 1
env: []
resources: {}
affinity: {}
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
maxBatchSize: "3"
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# processes: ""
# inputBlockSize: ""
# outputBlockSize: ""
maxBatchTimeMs: 750
# queuedMaxMessagesKbytes: ""
# queuedMinMessages: ""
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# volumes:
# - name: dshm
# emptyDir:
# medium: Memory
replacer:
enabled: true
replicas: 1
env: []
resources: {}
affinity: {}
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# autoOffsetReset: "earliest"
# maxBatchTimeMs: ""
# queuedMaxMessagesKbytes: ""
# queuedMinMessages: ""
# volumes: []
# volumeMounts: []
# noStrictOffsetReset: false
metricsConsumer:
enabled: true
replicas: 1
env: []
resources: {}
affinity: {}
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# autoOffsetReset: "earliest"
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumes: []
# volumeMounts: []
# maxBatchSize: ""
# processes: ""
# inputBlockSize: ""
# outputBlockSize: ""
maxBatchTimeMs: 750
# queuedMaxMessagesKbytes: ""
# queuedMinMessages: ""
# noStrictOffsetReset: false
subscriptionConsumerEvents:
enabled: true
replicas: 1
env: []
resources: {}
affinity: {}
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumes: []
# volumeMounts: []
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
genericMetricsCountersConsumer:
enabled: true
replicas: 1
env: []
resources: {}
affinity: {}
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# autoOffsetReset: "earliest"
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumes: []
# volumeMounts: []
# maxBatchSize: ""
# processes: ""
# inputBlockSize: ""
# outputBlockSize: ""
maxBatchTimeMs: 750
# queuedMaxMessagesKbytes: ""
# queuedMinMessages: ""
# noStrictOffsetReset: false
genericMetricsDistributionConsumer:
enabled: true
replicas: 1
env: []
resources: {}
affinity: {}
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# autoOffsetReset: "earliest"
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumes: []
# volumeMounts: []
# maxBatchSize: ""
# processes: ""
# inputBlockSize: ""
# outputBlockSize: ""
maxBatchTimeMs: 750
# queuedMaxMessagesKbytes: ""
# queuedMinMessages: ""
# noStrictOffsetReset: false
genericMetricsSetsConsumer:
enabled: true
replicas: 1
env: []
resources: {}
affinity: {}
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# autoOffsetReset: "earliest"
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumes: []
# volumeMounts: []
# maxBatchSize: ""
# processes: ""
# inputBlockSize: ""
# outputBlockSize: ""
maxBatchTimeMs: 750
# queuedMaxMessagesKbytes: ""
# queuedMinMessages: ""
# noStrictOffsetReset: false
subscriptionConsumerMetrics:
enabled: true
replicas: 1
env: []
resources: {}
# requests:
# cpu: 200m
# memory: 500Mi
affinity: {}
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# autoOffsetReset: "earliest"
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# volumes: []
# volumeMounts: []
subscriptionConsumerTransactions:
enabled: true
replicas: 1
env: []
resources: {}
# requests:
# cpu: 200m
# memory: 500Mi
affinity: {}
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# volumes: []
# volumeMounts: []
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# autoOffsetReset: "earliest"
# noStrictOffsetReset: false
replaysConsumer:
enabled: true
replicas: 1
env: []
resources: {}
affinity: {}
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# autoOffsetReset: "earliest"
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# maxBatchSize: ""
# processes: ""
# inputBlockSize: ""
# outputBlockSize: ""
maxBatchTimeMs: 750
# queuedMaxMessagesKbytes: ""
# queuedMinMessages: ""
# noStrictOffsetReset: false
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# volumes:
# - name: dshm
# emptyDir:
# medium: Memory
transactionsConsumer:
enabled: true
replicas: 1
env: []
resources: {}
affinity: {}
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# autoOffsetReset: "earliest"
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# maxBatchSize: ""
# processes: ""
# inputBlockSize: ""
# outputBlockSize: ""
maxBatchTimeMs: 750
# queuedMaxMessagesKbytes: ""
# queuedMinMessages: ""
# noStrictOffsetReset: false
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# volumes:
# - name: dshm
# emptyDir:
# medium: Memory
profilingProfilesConsumer:
replicas: 1
env: []
resources: {}
affinity: {}
sidecars: []
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# autoOffsetReset: "earliest"
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# maxBatchSize: ""
# processes: ""
# inputBlockSize: ""
# outputBlockSize: ""
maxBatchTimeMs: 750
# queuedMaxMessagesKbytes: ""
# queuedMinMessages: ""
# noStrictOffsetReset: false
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# volumes:
# - name: dshm
# emptyDir:
# medium: Memory
profilingFunctionsConsumer:
replicas: 1
env: []
resources: {}
affinity: {}
sidecars: []
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# autoOffsetReset: "earliest"
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# maxBatchSize: ""
# processes: ""
# inputBlockSize: ""
# outputBlockSize: ""
maxBatchTimeMs: 750
# queuedMaxMessagesKbytes: ""
# queuedMinMessages: ""
# noStrictOffsetReset: false
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# volumes:
# - name: dshm
# emptyDir:
# medium: Memory
issueOccurrenceConsumer:
enabled: true
replicas: 1
env: []
resources: {}
affinity: {}
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# autoOffsetReset: "earliest"
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# maxBatchSize: ""
# processes: ""
# inputBlockSize: ""
# outputBlockSize: ""
maxBatchTimeMs: 750
# queuedMaxMessagesKbytes: ""
# queuedMinMessages: ""
# noStrictOffsetReset: false
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# volumes:
# - name: dshm
# emptyDir:
# medium: Memory
spansConsumer:
enabled: true
replicas: 1
env: []
resources: {}
affinity: {}
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# autoOffsetReset: "earliest"
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# maxBatchSize: ""
# processes: ""
# inputBlockSize: ""
# outputBlockSize: ""
maxBatchTimeMs: 750
# queuedMaxMessagesKbytes: ""
# queuedMinMessages: ""
# noStrictOffsetReset: false
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# volumes:
# - name: dshm
# emptyDir:
# medium: Memory
groupAttributesConsumer:
enabled: true
replicas: 1
env: []
resources: {}
affinity: {}
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# autoOffsetReset: "earliest"
livenessProbe:
enabled: true
initialDelaySeconds: 5
periodSeconds: 320
# maxBatchSize: ""
# processes: ""
# inputBlockSize: ""
# outputBlockSize: ""
maxBatchTimeMs: 750
# queuedMaxMessagesKbytes: ""
# queuedMinMessages: ""
# noStrictOffsetReset: false
# volumeMounts:
# - mountPath: /dev/shm
# name: dshm
# volumes:
# - name: dshm
# emptyDir:
# medium: Memory
dbInitJob:
env: []
migrateJob:
env: []
clickhouse:
maxConnections: 100
rustConsumer: false
hooks:
enabled: true
preUpgrade: false
removeOnSuccess: true
activeDeadlineSeconds: 2000
shareProcessNamespace: false
dbCheck:
enabled: true
image:
# repository: subfuzion/netcat
# tag: latest
# pullPolicy: IfNotPresent
imagePullSecrets: []
env: []
# podLabels: {}
podAnnotations: {}
resources:
limits:
memory: 64Mi
requests:
cpu: 100m
memory: 64Mi
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
tolerations:
- key: "serv.type"
operator: "Equal"
value: "md"
effect: "NoSchedule"
nodeSelector: {}
securityContext: {}
containerSecurityContext: {}
# tolerations: []
# volumes: []
# volumeMounts: []
dbInit:
enabled: true
env: []
# podLabels: {}
podAnnotations: {}
resources:
limits:
memory: 2048Mi
requests:
cpu: 300m
memory: 2048Mi
sidecars: []
volumes: []
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
tolerations:
- key: "serv.type"
operator: "Equal"
value: "md"
effect: "NoSchedule"
nodeSelector: {}
# tolerations: []
# volumes: []
# volumeMounts: []
snubaInit:
enabled: true
# As snubaInit doesn't support configuring partition and replication factor, you can disable snubaInit's kafka topic creation by setting `kafka.enabled` to `false`,
# and create the topics using `kafka.provisioning.topics` with the desired partition and replication factor.
# Note that when you set `kafka.enabled` to `false`, snuba component might fail to start if newly added topics are not created by `kafka.provisioning`.
kafka:
enabled: true
# podLabels: {}
podAnnotations: {}
resources: {}
#limits:
# cpu: 2000m
# memory: 1Gi
#requests:
# cpu: 700m
# memory: 1Gi
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
tolerations:
- key: "serv.type"
operator: "Equal"
value: "md"
effect: "NoSchedule"
nodeSelector: {}
# tolerations: []
# volumes: []
# volumeMounts: []
snubaMigrate:
enabled: true
# podLabels: {}
# volumes: []
# volumeMounts: []
system:
## be sure to include the scheme on the url, for example: "https://sentry.example.com"
url: "https://sentry.htdevops.com"
adminEmail: "yingliang.feng@hannto.com"
## This should only be used if you’re installing Sentry behind your company’s firewall.
public: false
## This will generate one for you (it's must be given upon updates)
# secretKey: "xx"
mail:
# For example: smtp
backend: smtp
useTls: true
useSsl: false
username: "sentry.notify@hannto.com"
password: "HntSN2017"
# existingSecret: secret-name
## set existingSecretKey if key name inside existingSecret is different from 'mail-password'
# existingSecretKey: secret-key-name
port: 587
host: "smtp.partner.outlook.cn"
from: "sentry.notify@hannto.com"
symbolicator:
enabled: false
api:
usedeployment: true # Set true to use Deployment, false for StatefulSet
persistence:
enabled: true # Set true for using PersistentVolumeClaim, false for emptyDir
accessModes: ["ReadWriteOnce"]
storageClassName: "ksc-kfs"
size: "10Gi"
replicas: 1
env: []
probeInitialDelaySeconds: 10
resources: {}
affinity: {}
nodeSelector: {}
securityContext: {}
topologySpreadConstraints: []
containerSecurityContext: {}
# tolerations: []
# podLabels: {}
# priorityClassName: "xxx"
config: |-
# See: https://getsentry.github.io/symbolicator/#configuration
cache_dir: "/data"
bind: "0.0.0.0:3021"
logging:
level: "warn"
metrics:
statsd: null
prefix: "symbolicator"
sentry_dsn: null
connect_to_reserved_ips: true
# caches:
# downloaded:
# max_unused_for: 1w
# retry_misses_after: 5m
# retry_malformed_after: 5m
# derived:
# max_unused_for: 1w
# retry_misses_after: 5m
# retry_malformed_after: 5m
# diagnostics:
# retention: 1w
# TODO autoscaling in not yet implemented
autoscaling:
enabled: true
minReplicas: 2
maxReplicas: 5
targetCPUUtilizationPercentage: 50
# volumes: []
# volumeMounts: []
# sidecars: []
# TODO The cleanup cronjob is not yet implemented
cleanup:
enabled: false
# podLabels: {}
# affinity: {}
# env: []
# volumes: []
# sidecars: []
auth:
register: false
service:
name: sentry
type: ClusterIP
externalPort: 9000
annotations: {}
# externalIPs:
# - 192.168.0.1
# loadBalancerSourceRanges: []
# https://github.com/settings/apps (Create a Github App)
github: {}
# github:
# appId: "xxxx"
# appName: MyAppName
# clientId: "xxxxx"
# clientSecret: "xxxxx"
# privateKey: "-----BEGIN RSA PRIVATE KEY-----\nMIIEpA" !!!! Don't forget a trailing \n
# webhookSecret: "xxxxx"
#
# Note: if you use `existingSecret`, all above `clientId`, `clientSecret`, `privateKey`, `webhookSecret`
# params would be ignored, because chart will suppose that they are stored in `existingSecret`. So you
# must define all required keys and set it at least to empty strings if they are not needed in `existingSecret`
# secret (client-id, client-secret, webhook-secret, private-key)
#
# existingSecret: "xxxxx"
# existingSecretPrivateKeyKey: "" # by default "private-key"
# existingSecretWebhookSecretKey: "" # by default "webhook-secret"
# existingSecretClientIdKey: "" # by default "client-id"
# existingSecretClientSecretKey: "" # by default "client-secret"
#
# Reference -> https://docs.sentry.io/product/integrations/source-code-mgmt/github/
# https://developers.google.com/identity/sign-in/web/server-side-flow#step_1_create_a_client_id_and_client_secret
google: {}
# google:
# clientId: ""
# clientSecret: ""
# existingSecret: "xxxxx"
# existingSecretClientIdKey: "" # by default "client-id"
# existingSecretClientSecretKey: "" # by default "client-secret"
slack: {}
# slack:
# clientId: ""
# clientSecret: ""
# signingSecret: ""
# existingSecret: "xxxxx"
# existingSecretClientId: "" # by default "client-id"
# existingSecretClientSecret: "" # by default "client-secret"
# existingSecretSigningSecret: "" # by default "signing-secret"
# Reference -> https://develop.sentry.dev/integrations/slack/
discord: {}
# discord:
# applicationId: ""
# publicKey: ""
# clientSecret: ""
# botToken: ""
# existingSecret: "xxxxx"
# existingSecretApplicationId: "" # by default "application-id"
# existingSecretPublicKey: "" # by default "public-key"
# existingSecretClientSecret: "" # by default "client-secret"
# existingSecretBotToken: "" # by default "bot-token"
# Reference -> https://develop.sentry.dev/integrations/discord/
openai: {}
# existingSecret: "xxxxx"
# existingSecretKey: "" # by default "api-token"
nginx:
enabled: true # true, if Safari compatibility is needed
containerPort: 8080
existingServerBlockConfigmap: '{{ template "sentry.fullname" . }}'
resources: {}
replicaCount: 1
nodeSelector: {}
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "serv.type"
operator: In
values:
- md
tolerations:
- key: "serv.type"
operator: "Equal"
value: "md"
effect: "NoSchedule"
service:
type: ClusterIP
ports:
http: 80
extraLocationSnippet: false
customReadinessProbe:
tcpSocket:
port: http
initialDelaySeconds: 5
timeoutSeconds: 3
periodSeconds: 5
successThreshold: 1
failureThreshold: 3
# extraLocationSnippet: |
# location /admin {
# allow 1.2.3.4; # VPN network
# deny all;
# proxy_pass http://sentry;
# }
# Use this to enable an extra service account
# serviceAccount:
# create: false
# name: nginx
metrics:
serviceMonitor: {}
ingress:
enabled: true
# If you are using traefik ingress controller, switch this to 'traefik'
# if you are using AWS ALB Ingress controller, switch this to 'aws-alb'
# if you are using GKE Ingress controller, switch this to 'gke'
regexPathStyle: nginx
ingressClassName: ingress-nginx-ops
# If you are using AWS ALB Ingress controller, switch to true if you want activate the http to https redirection.
alb:
httpRedirect: false
# Add custom labels for ingress resource
# labels:
# annotations:
# If you are using nginx ingress controller, please use at least those 2 annotations
# kubernetes.io/ingress.class: nginx
# nginx.ingress.kubernetes.io/use-regex: "true"
# https://github.com/getsentry/self-hosted/issues/1927
# nginx.ingress.kubernetes.io/proxy-buffers-number: "16"
# nginx.ingress.kubernetes.io/proxy-buffer-size: "32k"
#
hostname: "sentry.htdevops.com"
# additionalHostNames: []
#
tls:
- secretName: "sentry-htdevops-com"
hosts:
- "sentry.htdevops.com"
filestore:
# Set to one of filesystem, gcs or s3 as supported by Sentry.
backend: filesystem
filesystem:
path: /var/lib/sentry/files
## Enable persistence using Persistent Volume Claims
## ref: http://kubernetes.io/docs/user-guide/persistent-volumes/
##
persistence:
enabled: true
## database data Persistent Volume Storage Class
## If defined, storageClassName: <storageClass>
## If set to "-", storageClassName: "", which disables dynamic provisioning
## If undefined (the default) or set to null, no storageClassName spec is
## set, choosing the default provisioner. (gp2 on AWS, standard on
## GKE, AWS & OpenStack)
##
storageClass: "ksc-kfs"
accessMode: ReadWriteMany # Set ReadWriteMany for work Replays
size: 10Gi
## Whether to mount the persistent volume to the Sentry worker and
## cron deployments. This setting needs to be enabled for some advanced
## Sentry features, such as private source maps. If you disable this
## setting, the Sentry workers will not have access to artifacts you upload
## through the web deployment.
## Please note that you may need to change your accessMode to ReadWriteMany
## if you plan on having the web, worker and cron deployments run on
## different nodes.
persistentWorkers: false
## If existingClaim is specified, no PVC will be created and this claim will
## be used
existingClaim: ""
gcs: {}
## Point this at a pre-configured secret containing a service account. The resulting
## secret will be mounted at /var/run/secrets/google
# secretName:
# credentialsFile: credentials.json
# bucketName:
## Currently unconfigured and changing this has no impact on the template configuration.
## Note that you can use a secret with default references "s3-access-key-id" and "s3-secret-access-key".
## Otherwise, you can use custom secret references, or use plain text values.
s3: {}
# existingSecret:
# accessKeyIdRef:
# secretAccessKeyRef:
# accessKey:
# secretKey:
# bucketName:
# endpointUrl:
# signature_version:
# region_name:
# default_acl:
config:
# No YAML Extension Config Given
configYml: {}
sentryConfPy: |
# No Python Extension Config Given
snubaSettingsPy: |
# No Python Extension Config Given
relay: |
# No YAML relay config given
web:
httpKeepalive: 15
maxRequests: 100000
maxRequestsDelta: 500
maxWorkerLifetime: 86400
clickhouse:
enabled: true
nodeSelector: {}
clickhouse:
replicas: "3"
configmap:
remote_servers:
internal_replication: true
replica:
backup:
enabled: true
zookeeper_servers:
enabled: true
config:
- index: "clickhouse"
hostTemplate: "{{ .Release.Name }}-zookeeper-clickhouse"
port: "2181"
users:
enabled: false
user:
# the first user will be used if enabled
- name: default
config:
password: "fVoQdJPbzkXCvUVNQLU3"
networks:
- ::/0
profile: default
quota: default
persistentVolumeClaim:
enabled: true
dataPersistentVolume:
enabled: true
storageClassName: "ksc-kfs"
accessModes:
- "ReadWriteMany"
storage: "30Gi"
## Use this to enable an extra service account
# serviceAccount:
# annotations: {}
# enabled: false
# name: "sentry-clickhouse"
# automountServiceAccountToken: true
## This value is only used when clickhouse.enabled is set to false
##
externalClickhouse:
## Hostname or ip address of external clickhouse
##
host: "clickhouse"
tcpPort: 9000
httpPort: 8123
username: default
password: ""
database: default
singleNode: true
# existingSecret: secret-name
## set existingSecretKey if key name inside existingSecret is different from 'postgres-password'
# existingSecretKey: secret-key-name
## Cluster name, can be found in config
## (https://clickhouse.tech/docs/en/operations/server-configuration-parameters/settings/#server-settings-remote-servers)
## or by executing `select * from system.clusters`
##
# clusterName: test_shard_localhost
# Settings for Zookeeper.
# See https://github.com/bitnami/charts/tree/master/bitnami/zookeeper
zookeeper:
enabled: true
nameOverride: zookeeper-clickhouse
replicaCount: 3
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: serv.type
operator: In
values:
- md
tolerations:
- key: "serv.type"
operator: "Equal"
value: "md"
effect: "NoSchedule"
nodeSelector: {}
# tolerations: []
## When increasing the number of exceptions, you need to increase persistence.size
# persistence:
# size: 8Gi
# Settings for Kafka.
# See https://github.com/bitnami/charts/tree/master/bitnami/kafka
kafka:
enabled: true
provisioning:
## Increasing the replicationFactor enhances data reliability during Kafka pod failures by replicating data across multiple brokers.
# Note that existing topics will remain with replicationFactor: 1 when updated.
replicationFactor: 3
enabled: true
# Topic list is based on files below.
# - https://github.com/getsentry/snuba/blob/master/snuba/utils/streams/topics.py
# - https://github.com/getsentry/sentry/blob/master/src/sentry/conf/types/kafka_definition.py
## Default number of partitions for topics when unspecified
##
# numPartitions: 1
# Note that snuba component might fail if you set `hooks.snubaInit.kafka.enabled` to `false` and remove the topics from this default topic list.
topics:
- name: events
## Number of partitions for this topic
# partitions: 1
config:
"message.timestamp.type": LogAppendTime
- name: event-replacements
- name: snuba-commit-log
config:
"cleanup.policy": "compact,delete"
"min.compaction.lag.ms": "3600000"
- name: cdc
- name: transactions
config:
"message.timestamp.type": LogAppendTime
- name: snuba-transactions-commit-log
config:
"cleanup.policy": "compact,delete"
"min.compaction.lag.ms": "3600000"
- name: snuba-metrics
config:
"message.timestamp.type": LogAppendTime
- name: outcomes
- name: outcomes-dlq
- name: outcomes-billing
- name: outcomes-billing-dlq
- name: ingest-sessions
- name: snuba-metrics-commit-log
config:
"cleanup.policy": "compact,delete"
"min.compaction.lag.ms": "3600000"
- name: scheduled-subscriptions-events
- name: scheduled-subscriptions-transactions
- name: scheduled-subscriptions-metrics
- name: scheduled-subscriptions-generic-metrics-sets
- name: scheduled-subscriptions-generic-metrics-distributions
- name: scheduled-subscriptions-generic-metrics-counters
- name: scheduled-subscriptions-generic-metrics-gauges
- name: events-subscription-results
- name: transactions-subscription-results
- name: metrics-subscription-results
- name: generic-metrics-subscription-results
- name: snuba-queries
config:
"message.timestamp.type": LogAppendTime
- name: processed-profiles
config:
"message.timestamp.type": LogAppendTime
- name: profiles-call-tree
- name: snuba-profile-chunks
- name: ingest-replay-events
config:
"message.timestamp.type": LogAppendTime
"max.message.bytes": "15000000"
- name: snuba-generic-metrics
config:
"message.timestamp.type": LogAppendTime
- name: snuba-generic-metrics-sets-commit-log
config:
"cleanup.policy": "compact,delete"
"min.compaction.lag.ms": "3600000"
- name: snuba-generic-metrics-distributions-commit-log
config:
"cleanup.policy": "compact,delete"
"min.compaction.lag.ms": "3600000"
- name: snuba-generic-metrics-counters-commit-log
config:
"cleanup.policy": "compact,delete"
"min.compaction.lag.ms": "3600000"
- name: snuba-generic-metrics-gauges-commit-log
config:
"cleanup.policy": "compact,delete"
"min.compaction.lag.ms": "3600000"
- name: generic-events
config:
"message.timestamp.type": LogAppendTime
- name: snuba-generic-events-commit-log
config:
"cleanup.policy": "compact,delete"
"min.compaction.lag.ms": "3600000"
- name: group-attributes
config:
"message.timestamp.type": LogAppendTime
- name: snuba-dead-letter-metrics
- name: snuba-dead-letter-generic-metrics
- name: snuba-dead-letter-replays
- name: snuba-dead-letter-generic-events
- name: snuba-dead-letter-querylog
- name: snuba-dead-letter-group-attributes
- name: ingest-attachments
- name: ingest-attachments-dlq
- name: ingest-transactions
- name: ingest-transactions-dlq
- name: ingest-transactions-backlog
- name: ingest-events-dlq
- name: ingest-events
## If the number of exceptions increases, it is recommended to increase the number of partitions for ingest-events
# partitions: 1
- name: ingest-replay-recordings
- name: ingest-metrics
- name: ingest-metrics-dlq
- name: ingest-performance-metrics
- name: ingest-feedback-events
- name: ingest-feedback-events-dlq
- name: ingest-monitors
- name: monitors-clock-tasks
- name: monitors-clock-tick
- name: monitors-incident-occurrences
- name: profiles
- name: ingest-occurrences
- name: snuba-spans
- name: snuba-eap-spans-commit-log
- name: scheduled-subscriptions-eap-spans
- name: eap-spans-subscription-results
- name: snuba-eap-mutations
- name: snuba-lw-deletions-generic-events
- name: shared-resources-usage
- name: snuba-profile-chunks
- name: buffered-segments
- name: buffered-segments-dlq
- name: uptime-configs
- name: uptime-results
- name: snuba-uptime-results
- name: task-worker
- name: snuba-ourlogs
listeners:
client:
protocol: "PLAINTEXT"
controller:
protocol: "PLAINTEXT"
interbroker:
protocol: "PLAINTEXT"
external:
protocol: "PLAINTEXT"
zookeeper:
enabled: false
kraft:
enabled: true
controller:
replicaCount: 3
nodeSelector: {}
# tolerations: []
## if the load on the kafka controller increases, resourcesPreset must be increased
# resourcesPreset: small # small, medium, large, xlarge, 2xlarge
## if the load on the kafka controller increases, persistence.size must be increased
# persistence:
# size: 8Gi
## Use this to enable an extra service account
# serviceAccount:
# create: false
# name: kafka
## Use this to enable an extra service account
# zookeeper:
# serviceAccount:
# create: false
# name: zookeeper
# sasl:
# ## Credentials for client communications.
# ## @param sasl.client.users ist of usernames for client communications when SASL is enabled
# ## @param sasl.client.passwords list of passwords for client communications when SASL is enabled, must match the number of client.users
# ## First user and password will be used if enabled
# client:
# users:
# - sentry
# passwords:
# - password
# ## @param sasl.enabledMechanisms Comma-separated list of allowed SASL mechanisms when SASL listeners are configured. Allowed types: `PLAIN`, `SCRAM-SHA-256`, `SCRAM-SHA-512`, `OAUTHBEARER`
# enabledMechanisms: PLAIN,SCRAM-SHA-256,SCRAM-SHA-512
# listeners:
# ## @param listeners.client.protocol Security protocol for the Kafka client listener. Allowed values are 'PLAINTEXT', 'SASL_PLAINTEXT', 'SASL_SSL' and 'SSL'
# client:
# protocol: SASL_PLAINTEXT
## This value is only used when kafka.enabled is set to false
##
externalKafka:
## Multi hosts and ports of external kafka
##
# cluster:
# - host: "233.5.100.28"
# port: 9092
# - host: "kafka-confluent-2"
# port: 9093
# - host: "kafka-confluent-3"
# port: 9094
## Or Hostname (ip address) of external kafka
# host: "kafka-confluent"
## and port of external kafka
# port: 9092
compression:
type: # 'gzip', 'snappy', 'lz4', 'zstd'
message:
max:
bytes: 50000000
sasl:
mechanism: None # PLAIN,SCRAM-256,SCRAM-512
username: None
password: None
security:
protocol: plaintext # 'PLAINTEXT', 'SASL_PLAINTEXT', 'SASL_SSL' and 'SSL'
socket:
timeout:
ms: 1000
sourcemaps:
enabled: false
redis:
enabled: false
replica:
replicaCount: 1
nodeSelector: {}
# tolerations: []
auth:
enabled: false
sentinel: false
## Just omit the password field if your redis cluster doesn't use password
# password: redis
# existingSecret: secret-name
## set existingSecretPasswordKey if key name inside existingSecret is different from redis-password'
# existingSecretPasswordKey: secret-key-name
nameOverride: sentry-redis
master:
persistence:
enabled: true
nodeSelector: {}
# tolerations: []
## Use this to enable an extra service account
# serviceAccount:
# create: false
# name: sentry-redis
## This value is only used when redis.enabled is set to false
##
externalRedis:
## Hostname or ip address of external redis cluster
##
host: "10.101.8.148"
port: 6379
## Just omit the password field if your redis cluster doesn't use password
password: ******
# existingSecret: secret-name
## set existingSecretKey if key name inside existingSecret is different from redis-password'
# existingSecretKey: secret-key-name
## Integer database number to use for redis (This is an integer)
db: 3
## Use ssl for the connection to Redis (True/False)
# ssl: false
postgresql:
enabled: false
nameOverride: sentry-postgresql
auth:
database: sentry
replication:
enabled: false
readReplicas: 2
synchronousCommit: "on"
numSynchronousReplicas: 1
applicationName: sentry
## Use this to enable an extra service account
# serviceAccount:
# enabled: false
## Default connection max age is 0 (unlimited connections)
## Set to a higher number to close connections after a period of time in seconds
connMaxAge: 0
## If you are increasing the number of replicas, you need to increase max_connections
# primary:
# extendedConfiguration: |
# max_connections=100
# nodeSelector: {}
# tolerations: []
## When increasing the number of exceptions, you need to increase persistence.size
# primary:
# persistence:
# size: 8Gi
## This value is only used when postgresql.enabled is set to false
## Set either externalPostgresql.password or externalPostgresql.existingSecret to configure password
externalPostgresql:
host: 10.102.3.229
port: 5432
username: sentry_admin
password: ******
# existingSecret: secret-name
# set existingSecretKeys in a secret, if not specified, value from the secret won't be used
# if externalPostgresql.existingSecret is used, externalPostgresql.existingSecretKeys.password must be specified.
existingSecretKeys: {}
# password: postgresql-password # Required if existingSecret is used. Key in existingSecret.
# username: username
# database: database
# port: port
# host: host
database: sentry_v25_3_0
# sslMode: require
## Default connection max age is 0 (unlimited connections)
## Set to a higher number to close connections after a period of time in seconds
connMaxAge: 0
rabbitmq:
## If disabled, Redis will be used instead as the broker.
enabled: false
vhost: /
clustering:
forceBoot: true
rebalance: true
replicaCount: 1
auth:
erlangCookie: pHgpy3Q6adTskzAT6bLHCFqFTF7lMxhA
username: guest
password: guest
nameOverride: ""
pdb:
create: true
persistence:
enabled: true
resources: {}
memoryHighWatermark: {}
# enabled: true
# type: relative
# value: 0.4
extraSecrets:
load-definition:
load_definition.json: |
{
"users": [
{
"name": "{{ .Values.auth.username }}",
"password": "{{ .Values.auth.password }}",
"tags": "administrator"
}
],
"permissions": [{
"user": "{{ .Values.auth.username }}",
"vhost": "/",
"configure": ".*",
"write": ".*",
"read": ".*"
}],
"policies": [
{
"name": "ha-all",
"pattern": ".*",
"vhost": "/",
"definition": {
"ha-mode": "all",
"ha-sync-mode": "automatic",
"ha-sync-batch-size": 1
}
}
],
"vhosts": [
{
"name": "/"
}
]
}
loadDefinition:
enabled: true
existingSecret: load-definition
extraConfiguration: |
load_definitions = /app/load_definition.json
## Use this to enable an extra service account
# serviceAccount:
# create: false
# name: rabbitmq
metrics:
enabled: false
serviceMonitor:
enabled: false
path: "/metrics/per-object" # https://www.rabbitmq.com/docs/prometheus
labels:
release: "prometheus-operator" # helm release of kube-prometheus-stack
memcached:
memoryLimit: "2048"
maxItemSize: "26214400"
args:
- "memcached"
- "-u memcached"
- "-p 11211"
- "-v"
- "-m $(MEMCACHED_MEMORY_LIMIT)"
- "-I $(MEMCACHED_MAX_ITEM_SIZE)"
extraEnvVarsCM: "sentry-memcached"
nodeSelector: {}
# tolerations: []
## Prometheus Exporter / Metrics
##
metrics:
enabled: false
podAnnotations: {}
## Configure extra options for liveness and readiness probes
## ref: https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-probes/#configure-probes)
livenessProbe:
enabled: true
initialDelaySeconds: 30
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
successThreshold: 1
readinessProbe:
enabled: true
initialDelaySeconds: 30
periodSeconds: 5
timeoutSeconds: 2
failureThreshold: 3
successThreshold: 1
## Metrics exporter resource requests and limits
## ref: http://kubernetes.io/docs/user-guide/compute-resources/
resources: {}
# limits:
# cpu: 100m
# memory: 100Mi
# requests:
# cpu: 100m
# memory: 100Mi
nodeSelector: {}
tolerations: []
affinity: {}
securityContext: {}
containerSecurityContext: {}
volumes: []
sidecars: []
# schedulerName:
# Optional extra labels for pod, i.e. redis-client: "true"
# podLabels: {}
service:
type: ClusterIP
labels: {}
image:
repository: hub.kce.ksyun.com/middleware/sentry-statsd-exporter
tag: v0.17.0
pullPolicy: IfNotPresent
imagePullSecrets:
- name: ksyunregistrykey
# Enable this if you're using https://github.com/coreos/prometheus-operator
serviceMonitor:
enabled: false
additionalLabels: {}
namespace: ""
namespaceSelector: {}
# Default: scrape .Release.Namespace only
# To scrape all, use the following:
# namespaceSelector:
# any: true
scrapeInterval: 30s
# honorLabels: true
relabelings: []
metricRelabelings: []
revisionHistoryLimit: 10
# dnsPolicy: "ClusterFirst"
# dnsConfig:
# nameservers: []
# searches: []
# options: []
extraManifests: []
pgbouncer:
enabled: false
postgres:
cp_max: 10
cp_min: 5
host: ''
dbname: ''
user: ''
password: ''
image:
repository: "bitnami/pgbouncer"
tag: "1.23.1-debian-12-r5"
pullPolicy: IfNotPresent
replicas: 2
podDisruptionBudget:
enabled: true
# Define either 'minAvailable' or 'maxUnavailable', never both.
minAvailable: 1
# -- Maximum unavailable pods set in PodDisruptionBudget. If set, 'minAvailable' is ignored.
# maxUnavailable: 1
authType: "md5"
maxClientConn: "8192"
poolSize: "50"
poolMode: "transaction"
resources: {}
nodeSelector: {}
tolerations: []
affinity: {}
updateStrategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 25%
priorityClassName: ''
topologySpreadConstraints: []
sentry/charts/clickhouse/values.yaml
遇到的问题
snuba-metrics-consumer 服务启动报错
snuba.clickhouse.errors.ClickhouseWriterError: Method write is not supported by storage Distributed with more than one shard and no sharding key provided (version 21.8.13.6 (official build))
原因: 新版本的 snuba 与 Clickhouse 表结构不对(最新直接部署的也是)
解决: 删除原表: default.metrics_raw_v2_dist,以新表重新构建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
$ kubectl exec -it sentry-clickhouse-0 -- bash
root@sentry-clickhouse-0:/# clickhouse-client -h sentry-clickhouse
ClickHouse client version 21.8.13.6 (official build).
Connecting to sentry-clickhouse:9000 as user default.
Connected to ClickHouse server version 21.8.13 revision 54449.
sentry-clickhouse :) SHOW TABLES;
SHOW TABLES
Query id: 00a56a30-1f3a-47bc-9017-0d7b0e753e32
┌─name───────────────────────────────────────────┐
│ discover_dist │
│ discover_local │
│ errors_dist │
│ errors_dist_ro │
│ errors_local │
│ functions_local │
│ functions_mv_dist │
│ functions_mv_local │
│ functions_raw_dist │
│ functions_raw_local │
│ generic_metric_counters_aggregated_dist │
│ generic_metric_counters_aggregated_local │
│ generic_metric_counters_aggregation_mv │
│ generic_metric_counters_aggregation_mv_v2 │
│ generic_metric_counters_raw_dist │
│ generic_metric_counters_raw_local │
│ generic_metric_distributions_aggregated_dist │
│ generic_metric_distributions_aggregated_local │
│ generic_metric_distributions_aggregation_mv │
│ generic_metric_distributions_aggregation_mv_v2 │
│ generic_metric_distributions_raw_dist │
│ generic_metric_distributions_raw_local │
│ generic_metric_gauges_aggregated_dist │
│ generic_metric_gauges_aggregated_local │
│ generic_metric_gauges_aggregation_mv │
│ generic_metric_gauges_raw_dist │
│ generic_metric_gauges_raw_local │
│ generic_metric_sets_aggregated_dist │
│ generic_metric_sets_aggregation_mv │
│ generic_metric_sets_aggregation_mv_v2 │
│ generic_metric_sets_local │
│ generic_metric_sets_raw_dist │
│ generic_metric_sets_raw_local │
│ group_attributes_dist │
│ group_attributes_local │
│ groupassignee_dist │
│ groupassignee_local │
│ groupedmessage_dist │
│ groupedmessage_local │
│ metrics_counters_polymorphic_mv_v4_local │
│ metrics_counters_v2_dist │
│ metrics_counters_v2_local │
│ metrics_distributions_polymorphic_mv_v4_local │
│ metrics_distributions_v2_dist │
│ metrics_distributions_v2_local │
│ metrics_raw_v2_dist │
│ metrics_raw_v2_local │
│ metrics_sets_polymorphic_mv_v4_local │
│ metrics_sets_v2_dist │
│ metrics_sets_v2_local │
│ migrations_dist │
│ migrations_local │
│ outcomes_hourly_dist │
│ outcomes_hourly_local │
│ outcomes_mv_hourly_local │
│ outcomes_raw_dist │
│ outcomes_raw_local │
│ profiles_dist │
│ profiles_local │
│ querylog_dist │
│ querylog_local │
│ replays_dist │
│ replays_local │
│ search_issues_dist │
│ search_issues_dist_v2 │
│ search_issues_local │
│ search_issues_local_v2 │
│ sessions_hourly_dist │
│ sessions_hourly_local │
│ sessions_hourly_mv_local │
│ sessions_raw_dist │
│ sessions_raw_local │
│ spans_dist │
│ spans_local │
│ test_migration_dist │
│ test_migration_local │
│ transactions_dist │
│ transactions_local │
└────────────────────────────────────────────────┘
78 rows in set. Elapsed: 0.012 sec.
sentry-clickhouse :) DESCRIBE TABLE default.metrics_raw_v2_dist;
DESCRIBE TABLE default.metrics_raw_v2_dist
Query id: 28daccfc-d3dc-4caa-8adc-3d2a08abf20d
┌─name────────────────────┬─type───────────────────┬─default_type─┬─default_expression─┬─comment─┬─codec_expression─┬─ttl_expression─┐
│ use_case_id │ LowCardinality(String) │ │ │ │ │ │
│ org_id │ UInt64 │ │ │ │ │ │
│ project_id │ UInt64 │ │ │ │ │ │
│ metric_id │ UInt64 │ │ │ │ │ │
│ timestamp │ DateTime │ │ │ │ │ │
│ tags.key │ Array(UInt64) │ │ │ │ │ │
│ tags.value │ Array(UInt64) │ │ │ │ │ │
│ metric_type │ LowCardinality(String) │ │ │ │ │ │
│ set_values │ Array(UInt64) │ │ │ │ │ │
│ count_value │ Float64 │ │ │ │ │ │
│ distribution_values │ Array(Float64) │ │ │ │ │ │
│ materialization_version │ UInt8 │ │ │ │ │ │
│ retention_days │ UInt16 │ │ │ │ │ │
│ partition │ UInt16 │ │ │ │ │ │
│ offset │ UInt64 │ │ │ │ │ │
│ timeseries_id │ UInt32 │ │ │ │ │ │
└─────────────────────────┴────────────────────────┴──────────────┴────────────────────┴─────────┴──────────────────┴────────────────┘
16 rows in set. Elapsed: 0.004 sec.
sentry-clickhouse :) SELECT COUNT(*) FROM default.metrics_raw_v2_dist;
SELECT COUNT(*)
FROM default.metrics_raw_v2_dist
Query id: 1d5e2a59-4f88-4274-80a1-828d4d0acbc1
┌─count()─┐
│ 0 │
└─────────┘
1 rows in set. Elapsed: 0.025 sec.
sentry-clickhouse :) DROP table default.metrics_raw_v2_dist ON CLUSTER 'sentry-clickhouse' SYNC;
DROP TABLE default.metrics_raw_v2_dist ON CLUSTER `sentry-clickhouse` NO DELAY
Query id: 83f1a44a-15dd-4491-97e5-b2dd16e31676
┌─host────────────────────────────────────────────────────────────────────┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ sentry-clickhouse-2.sentry-clickhouse-headless.sentry.svc.cluster.local │ 9000 │ 0 │ │ 2 │ 0 │
│ sentry-clickhouse-1.sentry-clickhouse-headless.sentry.svc.cluster.local │ 9000 │ 0 │ │ 1 │ 0 │
└─────────────────────────────────────────────────────────────────────────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
┌─host────────────────────────────────────────────────────────────────────┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ sentry-clickhouse-0.sentry-clickhouse-headless.sentry.svc.cluster.local │ 9000 │ 0 │ │ 0 │ 0 │
└─────────────────────────────────────────────────────────────────────────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
3 rows in set. Elapsed: 0.203 sec.
sentry-clickhouse :) CREATE TABLE default.metrics_raw_v2_dist ON CLUSTER 'sentry-clickhouse'
:-] (
:-] `use_case_id` LowCardinality(String),
:-] `org_id` UInt64,
:-] `project_id` UInt64,
:-] `metric_id` UInt64,
:-] `timestamp` DateTime,
:-] `tags.key` Array(UInt64),
:-] `tags.value` Array(UInt64),
:-] `metric_type` LowCardinality(String),
:-] `set_values` Array(UInt64),
:-] `count_value` Float64,
:-] `distribution_values` Array(Float64),
:-] `materialization_version` UInt8,
:-] `retention_days` UInt16,
:-] `partition` UInt16,
:-] `offset` UInt64,
:-] `timeseries_id` UInt32
:-] )
:-] ENGINE = Distributed('sentry-clickhouse', 'default', 'metrics_raw_v2_local', sipHash64('timeseries_id'));
CREATE TABLE default.metrics_raw_v2_dist ON CLUSTER `sentry-clickhouse`
(
`use_case_id` LowCardinality(String),
`org_id` UInt64,
`project_id` UInt64,
`metric_id` UInt64,
`timestamp` DateTime,
`tags.key` Array(UInt64),
`tags.value` Array(UInt64),
`metric_type` LowCardinality(String),
`set_values` Array(UInt64),
`count_value` Float64,
`distribution_values` Array(Float64),
`materialization_version` UInt8,
`retention_days` UInt16,
`partition` UInt16,
`offset` UInt64,
`timeseries_id` UInt32
)
ENGINE = Distributed('sentry-clickhouse', 'default', 'metrics_raw_v2_local', sipHash64('timeseries_id'))
Query id: 011e2e89-faea-4e14-88d7-68c7679c1293
┌─host────────────────────────────────────────────────────────────────────┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ sentry-clickhouse-2.sentry-clickhouse-headless.sentry.svc.cluster.local │ 9000 │ 0 │ │ 2 │ 0 │
│ sentry-clickhouse-1.sentry-clickhouse-headless.sentry.svc.cluster.local │ 9000 │ 0 │ │ 1 │ 0 │
│ sentry-clickhouse-0.sentry-clickhouse-headless.sentry.svc.cluster.local │ 9000 │ 0 │ │ 0 │ 0 │
└─────────────────────────────────────────────────────────────────────────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
3 rows in set. Elapsed: 0.253 sec.
BadGatewayError: GET /api/0/issues/{issueId}/attachments/ 502
加载所有事件的时候,报这个错
解决方式: All Events tab not loading #2340
原因:在Sentry-nginx前 有另外一个nginx, 因为事件太多处理失败,加个缓存,如下: ```
vi /etc/nginx/nginx.conf
1
2
3
proxy_buffering on;
proxy_buffer_size 128k;
proxy_buffers 4 256k; # service nginx restart ``` >> ingress-nginx修改配置 >> >>>在 ConfigMap: ingress-nginx-controller等类似配置文件, 在data下添加配置 >>> >>>``` >>>data: >>> proxy-buffering: "on" # 开启缓冲 >>> proxy-buffer-size: "128k" # 单个缓冲区大小 >>> proxy-buffers-number: "4" # 缓冲区数量 >>> proxy-buffers-size: "1024k" # 总缓冲区大小(4*256k=1024k) >>>```
SMTPRecipientsRefused: {‘Admin’: (501, b’5.1.3 Invalid address’)}
错误原因:Admin 是无效的邮箱地址(缺少 @ 符号和域名)。系统默认账号 Admin是无效的,可以删除
解决方法2种:
1.在初次部署Sentry时,直接设置正确的管理员账号
2.直接在web界面,删除 Admin账号即可
KafkaException sentry.sentry_metrics.consumers.indexer.multiprocess in poll
arroyo.errors.OffsetOutOfRange
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
kubectl -n sentry logs -f sentry-snuba-outcomes-billing-consumer-6cf8565ff-ddmhh
2025-05-29 14:08:04,795 Initializing Snuba...
2025-05-29 14:08:05,954 Snuba initialization took 1.1601227220003238s
2025-05-29 14:08:05,969 Consumer Starting
2025-05-29 14:08:05,969 Checking Clickhouse connections...
2025-05-29 14:08:05,982 Successfully connected to Clickhouse: cluster_name=sentry-clickhouse
2025-05-29 14:08:05,982 librdkafka log level: 6
2025-05-29 14:08:07,427 New partitions assigned: {Partition(topic=Topic(name='outcomes-billing'), index=0): 13870875}
2025-05-29 14:08:07,427 Member id: 'rdkafka-88065ac1-a2e9-44f7-ab6f-bacb2fee8aa0'
2025-05-29 14:08:07,430 Caught exception, shutting down...
Traceback (most recent call last):
File "/usr/local/lib/python3.11/site-packages/arroyo/processing/processor.py", line 334, in run
self._run_once()
File "/usr/local/lib/python3.11/site-packages/arroyo/processing/processor.py", line 401, in _run_once
self.__message = self.__consumer.poll(timeout=1.0)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/arroyo/backends/kafka/consumer.py", line 422, in poll
raise OffsetOutOfRange(str(error))
arroyo.errors.OffsetOutOfRange: KafkaError{code=_AUTO_OFFSET_RESET,val=-140,str="fetch failed due to requested offset not available on the broker: Broker: Offset out of range (broker 1)"}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
kubectl -n sentry logs -f sentry-ingest-consumer-transactions-79cdbf76f6-qvqrs
%4|1749198565.513|CONFWARN|rdkafka#consumer-1| [thrd:app]: Configuration property compression.codec is a producer property and will be ignored by this consumer instance
08:29:28 [INFO] arroyo.processing.processor: New partitions assigned: {Partition(topic=Topic(name='ingest-transactions'), index=0): 140029799}
08:29:28 [INFO] arroyo.processing.processor: Member id: 'rdkafka-1ceaa72f-3a78-4f00-acc8-6551e976474e'
Traceback (most recent call last):
File "/.venv/lib/python3.13/site-packages/arroyo/processing/processor.py", line 333, in run
self._run_once()
~~~~~~~~~~~~~~^^
File "/.venv/lib/python3.13/site-packages/arroyo/processing/processor.py", line 396, in _run_once
self.__message = self.__consumer.poll(timeout=1.0)
~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^
File "/.venv/lib/python3.13/site-packages/arroyo/backends/kafka/consumer.py", line 422, in poll
raise OffsetOutOfRange(str(error))
arroyo.errors.OffsetOutOfRange: KafkaError{code=_AUTO_OFFSET_RESET,val=-140,str="fetch failed due to requested offset not available on the broker: Broker: Offset out of range (broker 1)"}
08:29:28 [ERROR] arroyo.processing.processor: Caught exception, shutting down...
08:29:28 [INFO] arroyo.processing.processor: Closing <arroyo.backends.kafka.consumer.KafkaConsumer object at 0x7f67a74957f0>...
08:29:28 [INFO] arroyo.processing.processor: Partitions to revoke: [Partition(topic=Topic(name='ingest-transactions'), index=0)]
08:29:28 [INFO] arroyo.processing.processor: Partition revocation complete.
08:29:28 [INFO] arroyo.processing.processor: Processor terminated
Traceback (most recent call last):
File "/.venv/bin/sentry", line 4, in <module>
raise SystemExit(main())
~~~~^^
File "/usr/src/sentry/src/sentry/runner/main.py", line 144, in main
func(**kwargs)
~~~~^^^^^^^^^^
File "/.venv/lib/python3.13/site-packages/click/core.py", line 1157, in __call__
return self.main(*args, **kwargs)
~~~~~~~~~^^^^^^^^^^^^^^^^^
File "/.venv/lib/python3.13/site-packages/click/core.py", line 1078, in main
rv = self.invoke(ctx)
File "/.venv/lib/python3.13/site-packages/click/core.py", line 1688, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^
File "/.venv/lib/python3.13/site-packages/click/core.py", line 1688, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^
....
....
File "/.venv/lib/python3.13/site-packages/arroyo/processing/processor.py", line 333, in run
self._run_once()
~~~~~~~~~~~~~~^^
File "/.venv/lib/python3.13/site-packages/arroyo/processing/processor.py", line 396, in _run_once
self.__message = self.__consumer.poll(timeout=1.0)
~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^
File "/.venv/lib/python3.13/site-packages/arroyo/backends/kafka/consumer.py", line 422, in poll
raise OffsetOutOfRange(str(error))
arroyo.errors.OffsetOutOfRange: KafkaError{code=_AUTO_OFFSET_RESET,val=-140,str="fetch failed due to requested offset not available on the broker: Broker: Offset out of range (broker 1)"}
Sentry is attempting to send 2 pending events
Waiting up to 2 seconds
Press Ctrl-C to quit
即使使用 kafka直接重置还是报错
解决方法
1. 修改deployment: sentry-ingest-consumer-transactions 启动参数 - args: - run - consumer - ingest-transactions - --consumer-group - ingest-consumer - --auto-offset-reset # 增加配置 如果 offset 不存在,则从最早开始消费 latest - latest - --no-strict-offset-reset # 增加参数,则为true,如果不加则默认false - --healthcheck-file-path - /tmp/health.txt - -- 2. 启动后,再次:reset group offset(重头消费) kafka-consumer-groups.sh --bootstrap-server sentry-kafka.sentry.svc.cluster.local:9092 --group sentry-transactions-consumer --topic ingest-transactions --reset-offsets --to-earliest --execute WARN: No action will be performed as the --execute option is missing.In a future major release, the default behavior of this command will be to prompt the user before executing the reset rather than doing a dry run. You should add the --dry-run option explicitly if you are scripting this command and want to keep the current default behavior without prompting. Error: Assignments can only be reset if the group 'ingest-consumer' is inactive, but the current state is Stable. GROUP TOPIC PARTITION NEW-OFFSET -------- 原因:消费组正在消费,可以停止消费组 查看当前消费组详情 kafka-consumer-groups.sh --bootstrap-server sentry-kafka.sentry.svc.cluster.local:9092 --describe --group ingest-consumer GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID ingest-consumer ingest-attachments 0 - 0 - rdkafka-478779d5-0646-45a3-99e8-06149b0bb87d /10.3.2.141 rdkafka ingest-consumer ingest-events 0 26151 26151 0 rdkafka-fe864aa3-079b-43a0-8ae5-2bd94de3abc4 /10.3.2.146 rdkafka ingest-consumer ingest-transactions 0 464517170 465625755 1108585 - - - 解决:副本数置零,当次topic完全停止消费后,再恢复原副本数,发现不报错了。 ========================================= ### 如果不知道groupID,列出所有的 kafka-consumer-groups.sh --bootstrap-server sentry-kafka.sentry.svc.cluster.local:9092 --list
执行 offset 重置异常
列出当前消费组
查看topic是否有动态配置
查看topic详细配置
查看消费组详情
启动消费者后:

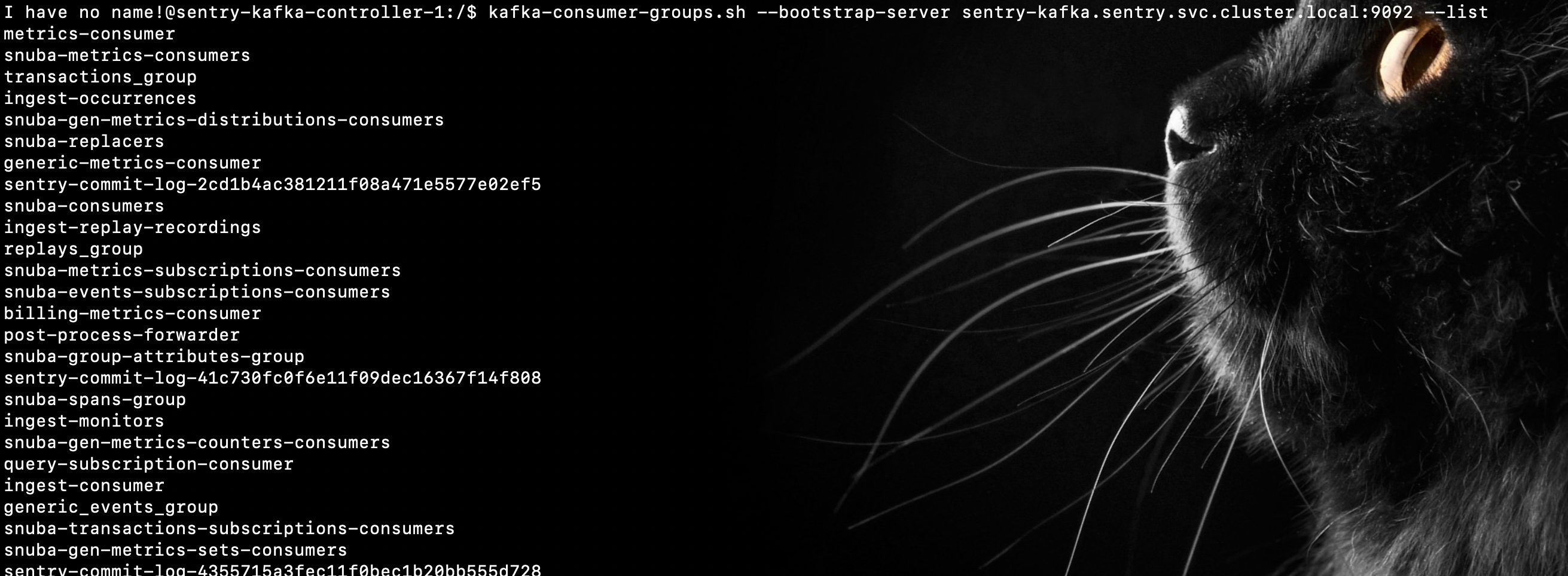




本文由作者按照
CC BY 4.0
进行授权