命令功能详情
1. curl
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
-s : 结果不显示统计信息,参数将不输出错误和进度信息。
-m : 允许的最多传输时间
连接websocket
curl --no-buffer -H 'Connection: keep-alive, Upgrade' -H 'Upgrade: websocket' -v -H 'Sec-WebSocket-Version: 13' -H 'Sec-WebSocket-Key: websocket' http://loacahost:8288 ws| od -t c
批量请求
curl http://domain/#/statistic/data-screening-new/index/?[1-500]
/?[1-500] 参数后面加数字, 会访问此地址500次
请求返回状态
curl -sIL -w "%{http_code}\n" -o /dev/null https://baidu.com
curl -I -m 5 -s -w "%{http_code}" -o /dev/null baidu.com
-I 只返回头信息
-L 访问带有跳转性质的网站, 同时为了避免当资源过大请求缓慢的情况
-w 格式化输出 reponse 的返回结果
-o 隐藏掉打印信息
指定请求参数
curl '127.0.0.1/print_param?a=1&b=2%26' -d 'c=3&d=4%26'
-d 参数用于发送 POST 请求的数据体
代理访问
curl --proxy 1.1.1.1:80 https://www.baidu.com
curl -x 1.1.1.1:80 https://www.baidu.com
-x 使用代理访问,等同--proxy
2. rsync
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
rsync -avr --progress -e "ssh -p 10022" root@192.168.11.111:/usr/local/OpenResty1.17/nginx/logs/*.log fscloude_log/
-a: 归档模式,表示以递归方式传输文件,并保持所有文件属性
-v: 详细模式输出
-r: 对子目录以递归模式处理
--progress: 显示备份过程
--exclude: 排除文件、文件夹、文件夹下的文件不排除文件夹
--exclude 'file.txt'
--exclude 'dir'
--exclude 'dir/*'
rsync -a --exclude 'dir1' src_directory/ dst_directory/
#指定端口拷贝
rsync -aP -e 'ssh -p 2288' ssh-audit.dat 172.18.18.31:/opt/freesvr/audit/sshgw-audit/sbin
具体参数
-v, --verbose 详细模式输出
-q, --quiet 精简输出模式
-c, --checksum 打开校验开关,强制对文件传输进行校验
-a, --archive 归档模式,表示以递归方式传输文件,并保持所有文件属性,等于-rlptgoD
-r, --recursive 对子目录以递归模式处理
-R, --relative 使用相对路径信息
-b, --backup 创建备份,也就是对于目的已经存在有同样的文件名时,将老的文件重新命名为~filename。可以使用--suffix选项来指定不同的备份文件前缀。
--backup-dir 将备份文件(如~filename)存放在在目录下。
-suffix=SUFFIX 定义备份文件前缀
-u, --update 仅仅进行更新,也就是跳过所有已经存在于DST,并且文件时间晚于要备份的文件。(不覆盖更新的文件)
-l, --links 保留软链结
-L, --copy-links 想对待常规文件一样处理软链结
--copy-unsafe-links 仅仅拷贝指向SRC路径目录树以外的链结
--safe-links 忽略指向SRC路径目录树以外的链结
-H, --hard-links 保留硬链结
-p, --perms 保持文件权限
-o, --owner 保持文件属主信息
-g, --group 保持文件属组信息
-D, --devices 保持设备文件信息
-t, --times 保持文件时间信息
-S, --sparse 对稀疏文件进行特殊处理以节省DST的空间
-n, --dry-run现实哪些文件将被传输
-W, --whole-file 拷贝文件,不进行增量检测
-x, --one-file-system 不要跨越文件系统边界
-B, --block-size=SIZE 检验算法使用的块尺寸,默认是700字节
-e, --rsh=COMMAND 指定使用rsh、ssh方式进行数据同步
--rsync-path=PATH 指定远程服务器上的rsync命令所在路径信息
-C, --cvs-exclude 使用和CVS一样的方法自动忽略文件,用来排除那些不希望传输的文件
--existing 仅仅更新那些已经存在于DST的文件,而不备份那些新创建的文件
--delete 删除那些DST中SRC没有的文件
--delete-excluded 同样删除接收端那些被该选项指定排除的文件
--delete-after 传输结束以后再删除
--ignore-errors 及时出现IO错误也进行删除
--max-delete=NUM 最多删除NUM个文件
--partial 保留那些因故没有完全传输的文件,以是加快随后的再次传输
--force 强制删除目录,即使不为空
--numeric-ids 不将数字的用户和组ID匹配为用户名和组名
--timeout=TIME IP超时时间,单位为秒
-I, --ignore-times 不跳过那些有同样的时间和长度的文件
--size-only 当决定是否要备份文件时,仅仅察看文件大小而不考虑文件时间
--modify-window=NUM 决定文件是否时间相同时使用的时间戳窗口,默认为0
-T --temp-dir=DIR 在DIR中创建临时文件
--compare-dest=DIR 同样比较DIR中的文件来决定是否需要备份
-P 等同于 --partial
--progress 显示备份过程
-z, --compress 对备份的文件在传输时进行压缩处理
--exclude=PATTERN 指定排除不需要传输的文件模式
--include=PATTERN 指定不排除而需要传输的文件模式
--exclude-from=FILE 排除FILE中指定模式的文件
--include-from=FILE 不排除FILE指定模式匹配的文件
--version 打印版本信息
--address 绑定到特定的地址
--config=FILE 指定其他的配置文件,不使用默认的rsyncd.conf文件
--port=PORT 指定其他的rsync服务端口
--blocking-io 对远程shell使用阻塞IO
-stats 给出某些文件的传输状态
--progress 在传输时现实传输过程
--log-format=formAT 指定日志文件格式
--password-file=FILE 从FILE中得到密码
--bwlimit=KBPS 限制I/O带宽,KBytes per second
-h, --help 显示帮助信息
增量同步
rsync -avzu --progress /opt/* devops@11.0.10.8:/opt/
自定义端口
'-e ssh -p 端口'
rsync -avzu --progress '-e ssh -p 端口' /opt/* devops@11.0.10.8:/opt/
完全同步
rsync -arvogp --delete --progress /opt/* devops@11.0.10.8:/opt/
3. grep
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
-a: 匹配二进制
-i: 忽略大小写
匹配隐藏文件
grep -r search * .*
显示匹配行及n行之后的内容
-A
grep -A3 content filename
显示匹配行及n行之前的内容
-B
grep -B3 content filename
[root@linux ~]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 S 0 5881 5654 0 76 0 - 1303 wait pts/0 00:00:00 su
4 S 0 5882 5881 0 75 0 - 1349 wait pts/0 00:00:00 bash
4 R 0 6037 5882 0 76 0 - 1111 - pts/0 00:00:00 ps
# 上面这个信息其实很多喔!各相关信息的意义为:
# F 代表这个程序的旗标 (flag), 4 代表使用者为 super user;
# S 代表这个程序的状态 (STAT),关于各 STAT 的意义将在内文介绍;
# PID 没问题吧!?就是这个程序的 ID 啊!底下的 PPID 则上父程序的 ID;
# C CPU 使用的资源百分比
# PRI 这个是 Priority (优先执行序) 的缩写,详细后面介绍;
# NI 这个是 Nice 值,在下一小节我们会持续介绍。
# ADDR 这个是 kernel function,指出该程序在内存的那个部分。如果是个 running
# 的程序,一般就是『 - 』的啦!
# SZ 使用掉的内存大小;
# WCHAN 目前这个程序是否正在运作当中,若为 - 表示正在运作;
# TTY 登入者的终端机位置啰;
# TIME 使用掉的 CPU 时间。
# CMD 所下达的指令为何!?
# 仔细看到每一个程序的 PID 与 PPID 的相关性为何喔!上头列出的三个程序中,
# 彼此间可是有相关性的吶!
# 匹配: 至少3个大写字母-(一位或多位)纯数字,并输出匹配的内容
grep -o '[A-Z]\{3,\}-[0-9]\+' file.txt
-v: 逆反模示, 只输出"不含" RE 字符串之句子.
-r: 递归模式, 可同时处理所有层级子目录里的文件.
-q: 静默模式, 不输出任何结果(stderr 除外. 常用以获取 return value, 符合为 true, 否则为 false .)
-i: 忽略大小写.
-w: 整词比对, 类似 \<word\> .
-n: 同时输出行号.
-c: 只输出符合比对的行数.
-l: 只输出符合比对的文件名称.
-o: 只输出符合 RE 的字符串. (gnu 新版独有, 不见得所有版本都支持.)
-E: 切换为 egrep
排除 行首为##(包含非第一列)、空行
grep -vE "^\s*#|^$"
4. git
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
进入git项目的本地文件夹,将自己的项目复制到这个git 文件夹,查看状态,提交所有的新文件
git status
git add .
git commit -m"first commit"
git tag -a "标签内容" -m "提交内容"
推送标签
git push --tags
撤销git add 内容
git reset .
或者
git status 根据提示执行对应文件的处理方法
上传更新到git 版本库
git push
清除工作区和暂存区,没有进行 add . 和 commit 操作:
$ git checkout .
git add -A 提交所有变化
git add -u 提交被修改(modified)和被删除(deleted)文件,不包括新文件(new)
git add . 提交新文件(new)和被修改(modified)文件,不包括被删除(deleted)文件
推送的时候遇到问题:
[root@oa faq]# git add .
warning: You ran 'git add' with neither '-A (--all)' or '--ignore-removal',
whose behaviour will change in Git 2.0 with respect to paths you removed.
Paths like 'template/22/images/耳机网站.zip' that are
removed from your working tree are ignored with this version of Git.
* 'git add --ignore-removal <pathspec>', which is the current default,
ignores paths you removed from your working tree.
* 'git add --all <pathspec>' will let you also record the removals.
Run 'git status' to check the paths you removed from your working tree.
#按照提示执行 使用 -A 或 -all
[root@oa faq]# git add -A
[root@oa faq]# git commit -m "同步生产至远端"
*** Please tell me who you are.
Run
git config --global user.email "you@example.com"
git config --global user.name "Your Name"
to set your account's default identity.
Omit --global to set the identity only in this repository.
fatal: unable to auto-detect email address (got 'root@oa.(none)')
#按照提示执行
[root@oa faq]# git config --global user.email "oa-online-serv@oa-online-serv"
[root@oa faq]# git config --global user.name "oa-online-serv"
[root@oa faq]# git commit -m "同步生产至远端"
[root@oa faq]# git push
warning: push.default is unset; its implicit value is changing in
Git 2.0 from 'matching' to 'simple'. To squelch this message
and maintain the current behavior after the default changes, use:
git config --global push.default matching
To squelch this message and adopt the new behavior now, use:
git config --global push.default simple
See 'git help config' and search for 'push.default' for further information.
(the 'simple' mode was introduced in Git 1.7.11. Use the similar mode
'current' instead of 'simple' if you sometimes use older versions of Git)
> GitLab: You are not allowed to push code to this project.
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.
#按照提示执行
[root@oa faq]# git config --global push.default matching
[root@oa faq]# git push
> GitLab: You are not allowed to push code to this project.
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.
#没用推送权限,开启权限,再次推送
# 查看文件当前转态(左边: 暂存区; 右边: 本地文件)
git status -s
A: 你本地新增的文件(服务器上没有).
C: 文件的一个新拷贝.
D: 你本地删除的文件(服务器上还在).
M: 文件的内容或者mode被修改了.
R: 文件名被修改了
T: 文件的类型被修改了
U: 文件没有被合并(你需要完成合并才能进行提交)
X: 未知状态(很可能是遇到git的bug了,你可以向git提交bug report)
?:未被git进行管理,可以使用git add file1把file1添加进git能被git所进行管理
#从暂存区移除文件
git reset HEAD -- path/filename
从暂存区移除文件夹下的所有文件
git reset HEAD -- .
5. sort
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
sort -nr | uniq -c | sort -nk 2
-n 依照数值的大小排序
-r 以相反的顺序来排序
-k n 以第n列数据排序
-t "|" 以 "|" 分隔符排序
排序
sort -t $'\t' -k 1n,1 -k 2n,2 -k4rn,4 -k3,3 <my-file>
解释如下:
-t $'\t':指定TAB为分隔符
-k 1, 1: 按照第一列的值进行排序,如果只有一个1的话,相当于告诉sort从第一列开始直接到行尾排列
n:代表是数字顺序,默认情况下市字典序,如10<2
r: reverse 逆序排列,默认情况下市正序排列
6. sed
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
# 删除第N行
# N为行数
sed -i 'Nd' filename
sed -i 'Nd' filename
# 删除文档的第一行
sed -i '1d' <file>
# 删除文档的最后一行
sed -i '$d' <file>
# 删除从第4行到第8行
sed -i '4,8d' a.txt
# 替换
sed -i 's/NUM/number/i' 文件名 # 忽略大小写
sed -i 's/NUM/number/g' 文件名 # 不忽略大小写
sed -i 's?NUM?number?g' 文件名 #如果匹配文档中有 "/",可以换成其他符号,只要不是在shell中有特殊定义的
# 行尾替换
sed -i '/test/ s/$/000/' 文件名
# 删除匹配行
sed ‘/toMatch/d’ filename
# 匹配行 行首加 "#"
sed -i '/LOCAL_RECORDDIR/s/^#//' /opt/fs/oss_upload/main.sh
# 匹配行替换整行: 变量中间有/ , sed: 匹配模式: "#", 变量用单引号引用
LOCAL_RECORDDIR="/var/log/freeswitch/${IPDDR}/data/fs_callrecord"
sed -i -e 's#^LOCAL_RECORDDIR.*#LOCAL_RECORDDIR=''${LOCAL_RECORDDIR}''#' /opt/fs/oss_upload/main.sh
7. awk
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
函数名 返回值
atan2(x,y) 值域内y/x的反正切
cos(x) x的余弦,x为弧度
exp(x) x的e指数函数
int(x) x的整数部分,当x>0时,向下取整
log(x) x的自然对数(底数为e)
rand() 随机数r(0<r<1)< td="">
sin(x) x的正弦,x为弧度
sqrt(x) x的平方根
srand(x) x是rand()的新种子
NF:支持记录域个数, 分隔符分开之后的列值
NR:已经读取的记录数
awk统计某列重复出现的次数: 以第6列为准
awk -F '[,:]' '{a[$6]++} END{for(i in a)print i,a[i]}' filename
取最大值、最小值: 以第6为不变, 取第11列的最大、小值
awk '{max[$6]=max[$6]>$(11)?max[$6]:$(11)}END{for(i in max)print i,max[i]}' filename
awk '{if(!min[$6])min[$6]=12345;min[$6]=min[$6]<$(11)?min[$6]:$(11)}END{for(i in min)print i,min[i]}' filename
求和、平均值: 以第6为不变, 取第11列的和、平均值
awk -F '|' '{s[$6] += $(11)} END{for(i in s) print i, s[i]} }' srcFile
awk -F '|' '{s[$6] += $(11)} END{for(i in s) print i, s[i]}/NR }' filename
合在一起
awk -F"|" '{times[$6]++; max[$6]=max[$6]>$(11)?max[$6]:$(11); if(!min[$6])min[$6]=100;min[$6]=min[$6]<$(11)?min[$6]:$(11)} END{for( i in times ){print i"|"times[i]"|"max[i]"|"min[i]}}' filename
传外部变量
-v key=value
A=1;B=2
awk -v A=$A -v B=$B '{printf("%.2f\n",A/B)}'
8. cut
1
2
3
4
5
# 获取月: 20201126
echo $file | awk -F"." '{print $NF}' | cut -c1-6 | sort | uniq
-d . 以 . 为分隔符
-f 2- 与 -d 搭配使用
9. sar
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
实时网卡流量
sar -n DEV 1 2
[root@test2 conf]# sar -n DEV 1 2
Linux 3.10.0-693.2.2.el7.x86_64 (test2) 11/27/2020 _x86_64_ (4 CPU)
03:31:04 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
03:31:05 PM eth0 73.00 106.00 6.97 15.79 0.00 0.00 0.00
03:31:05 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
03:31:05 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
03:31:06 PM eth0 78.00 113.00 9.97 15.69 0.00 0.00 0.00
03:31:06 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
Average: eth0 75.50 109.50 8.47 15.74 0.00 0.00 0.00
Average: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
-n: 对网络使用情况进行显示
DEV: 显示网络接口信息
1 2: 每一秒钟取1次值,取2次
-n 的几个参数:
DEV 显示网络接口信息。
EDEV 显示关于网络错误的统计数据。
NFS 统计活动的NFS客户端的信息。
NFSD 统计NFS服务器的信息
SOCK 显示套接字信息
ALL 显示所有5个开关
显示参数说明:
IFACE:LAN接口
rxpck/s:每秒钟接收的数据包
txpck/s:每秒钟发送的数据包
rxbyt/s:每秒钟接收的字节数
txbyt/s:每秒钟发送的字节数
rxcmp/s:每秒钟接收的压缩数据包
txcmp/s:每秒钟发送的压缩数据包
rxmcst/s:每秒钟接收的多播数据包
rxerr/s:每秒钟接收的坏数据包
txerr/s:每秒钟发送的坏数据包
coll/s:每秒冲突数
rxdrop/s:因为缓冲充满,每秒钟丢弃的已接收数据包数
txdrop/s:因为缓冲充满,每秒钟丢弃的已发送数据包数
txcarr/s:发送数据包时,每秒载波错误数
rxfram/s:每秒接收数据包的帧对齐错误数
rxfifo/s:接收的数据包每秒FIFO过速的错误数
txfifo/s:发送的数据包每秒FIFO过速的错误数
10. pkill
1
2
# 关闭指定 ssh 连接
pkill -kill -t pts/1
11. iftop
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
查看带宽占用情况
yum install iftop
#查看eth0显卡的带宽占用
iftop -i eth0 -P
-h: 切换是否显示帮助;
-n: 切换显示本机的IP或主机名;
-s: 切换是否显示本机的host信息;
-d: 切换是否显示远端目标主机的host信息;
-t: 切换显示格式为2行/1行/只显示发送流量/只显示接收流量;
-N: 切换显示端口号或端口服务名称;
-S: 切换是否显示本机的端口信息;
-D: 切换是否显示远端目标主机的端口信息;
-p: 切换是否显示端口信息;
-P: 切换暂停/继续显示;
-b: 切换是否显示平均流量图形条;
-B: 切换计算2秒或10秒或40秒内的平均流量;
-T: 切换是否显示每个连接的总流量;
-l: 打开屏幕过滤功能,输入要过滤的字符,比如ip,按回车后,屏幕就只显示这个IP相关的流量信息;
L: 切换显示画面上边的刻度;刻度不同,流量图形条会有变化;
j: 或按k可以向上或向下滚动屏幕显示的连接记录;
1: 或2或3可以根据右侧显示的三列流量数据进行排序;
<: 根据左边的本机名或IP排序;
>: 根据远端目标主机的主机名或IP排序;
o: 切换是否固定只显示当前的连接;
f: 可以编辑过滤代码;
!: 可以使用shell命令;
q: 退出监控。
12. crontab
1
2
3
4
5
6
7
8
9
10
11
12
* * * * *
- - - - -
| | | | |
| | | | +----- 星期中星期几 (0 - 7) (星期天 为0)
| | | +---------- 月份 (1 - 12)
| | +--------------- 一个月中的第几天 (1 - 31)
| +-------------------- 小时 (0 - 23)
+------------------------- 分钟 (0 - 59)
#使用 date 获取当前时间
3 7 * * * /usr/bin/rsync -az /var/log/sample.log-$(date +"\%Y\%m\%d")
13. unzip
1
2
解压 **.war
unzip **.war -d 文件夹名
14. nc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
-g<网关> 设置路由器跃程通信网关,最多可设置8个。
-G<指向器数目> 设置来源路由指向器,其数值为4的倍数。
-h 在线帮助。
-i<延迟秒数> 设置时间间隔,以便传送信息及扫描通信端口。
-l 使用监听模式,管控传入的资料。
-n 直接使用IP地址,而不通过域名服务器。
-o<输出文件> 指定文件名称,把往来传输的数据以16进制字码倾倒成该文件保存。
-p<通信端口> 设置本地主机使用的通信端口。
-r 乱数指定本地与远端主机的通信端口。
-s<来源位址> 设置本地主机送出数据包的IP地址。
-u 使用UDP传输协议。
-v 显示指令执行过程。
-w<超时秒数> 设置等待连线的时间。
-z 使用0输入/输出模式,只在扫描通信端口时使用。
IP_ADD=$1
PORT=$2
TIME_THRESHOLD=$3
nc -w $TIME_THRESHOLD $1 -z $2
nc -w 3 172.17.3.9 -z 3306
nc -zv 172.17.3.9 3306
测试UDP端口
nc -zvu 192.168.50.66 8888
# 互相发送udp包
1. 服务端:
ip:port: 172.19.255.111:62202
开启端口: nc -u -l 62202
2. 客户端:
发送数据: echo "test package" | nc -u 172.19.255.111 62202
15. iptables
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
--state:指定数据包的状态,常见的状态有:
INVALID:无效的数据包状态
ESTABLISHED:已经连接成功的数据包状态
NEW:想要新建立连接的数据包状态
RELATED:这个最常用,它表示该数据包与我们主机发送出去的数据包有关
-m:指定 iptables 的插件模块,常见的模块有:
state:状态模块
mac:处理网卡硬件地址(hardware address)的模块
--sport:限制来源的端口号,可以是单个端口,也可以是一个范围,如 1024:1050
--dport:限制目标的端口号。
注意,因为只有 tcp 协议和 udp 协议使用了端口号,所以在使用 --sport 和 --dport 时,一定要指定协议的类型(-p tcp 或 -p udp)。
#直接在命令行往指定位置添加开放端口
iptables -I INPUT 4 -s 111.111.111.111/32 -p tcp -m state --state NEW -m tcp --dport 5002 -j ACCEPT
#查看对应规则的编号
iptables -t nat -L -n --line-numbers
iptables -t nat -L PREROUTING -n --line-numbers
#删除对应编号的规则
iptables -t nat -D PREROUTING 2
iptables -D INPUT -s 1.194.235.182 -j DROP
#开启域名ping:指定位置
iptables -I INPUT 1804 -s 0.0.0.0/0 -p icmp -j ACCEPT
#iptables规则
REJECT 拦阻该数据包,并返回数据包通知对方,可以返回的数据包有几个选择:ICMP port-unreachable、ICMP echo-reply 或是tcp-reset(这个数据包包会要求对方关闭联机),进行完此处理动作后,将不再比对其它规则,直接中断过滤程序。 范例如下:
iptables -A INPUT -p TCP --dport 22 -j REJECT --reject-with ICMP echo-reply
DROP 丢弃数据包不予处理,进行完此处理动作后,将不再比对其它规则,直接中断过滤程序。
REDIRECT 将封包重新导向到另一个端口(PNAT),进行完此处理动作后,将会继续比对其它规则。这个功能可以用来实作透明代理 或用来保护web 服务器。例如:
iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT--to-ports 8081
LOG 将数据包相关信息纪录在 /var/log 中,详细位置请查阅 /etc/syslog.conf 配置文件,进行完此处理动作后,将会继续比对其它规则。例如:
iptables -A INPUT -p tcp -j LOG --log-prefix "input packet"
SNAT 改写封包来源 IP 为某特定 IP 或 IP 范围,可以指定 port 对应的范围,进行完此处理动作后,将直接跳往下一个规则炼(mangle:postrouting)。范例如下:
iptables -t nat -A POSTROUTING -p tcp -o eth0 -j SNAT --to-source 192.168.10.15-192.168.10.160:2100-3200
DNAT 改写数据包包目的地 IP 为某特定 IP 或 IP 范围,可以指定 port 对应的范围,进行完此处理动作后,将会直接跳往下一个规则链(filter:input 或 filter:forward)。范例如下:
iptables -t nat -A PREROUTING -p tcp -d 15.45.23.67 --dport 80 -j DNAT --to-destination 192.168.10.1-192.168.10.10:80-100
MIRROR 镜像数据包,也就是将来源 IP与目的地IP对调后,将数据包返回,进行完此处理动作后,将会中断过滤程序
QUEUE 中断过滤程序,将封包放入队列,交给其它程序处理。透过自行开发的处理程序,可以进行其它应用,例如:计算联机费用.......等
RETURN 结束在目前规则链中的过滤程序,返回主规则链继续过滤
MARK 将封包标上某个代号,以便提供作为后续过滤的条件判断依据,进行完此处理动作后,将会继续比对其它规则。范例如下:
iptables -t mangle -A PREROUTING -p tcp --dport 22 -j MARK --set-mark 22
16. read
1
2
3
-e: 命令补全
-p: 输入提示
17. nmap
1
2
3
4
5
6
7
Open(开放的)意味着目标机器上的应用程序正在该端口监听连接 / 报文。
filtered(被过滤的) 意味着防火墙,过滤器或者其它网络障碍阻止了该端口被访问,Nmap 无法得知 它是 open(开放的) 还是 closed(关闭的)。
closed(关闭的) 端口没有应用程序在它上面监听,但是他们随时可能开放。
unfiltered(未被过滤的)当端口对 Nmap 的探测做出响应,但是 Nmap 无法确定它们是关闭还是开放时
显示当前主机的开放端口
iostat -sT -O localhost
18. mtr
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
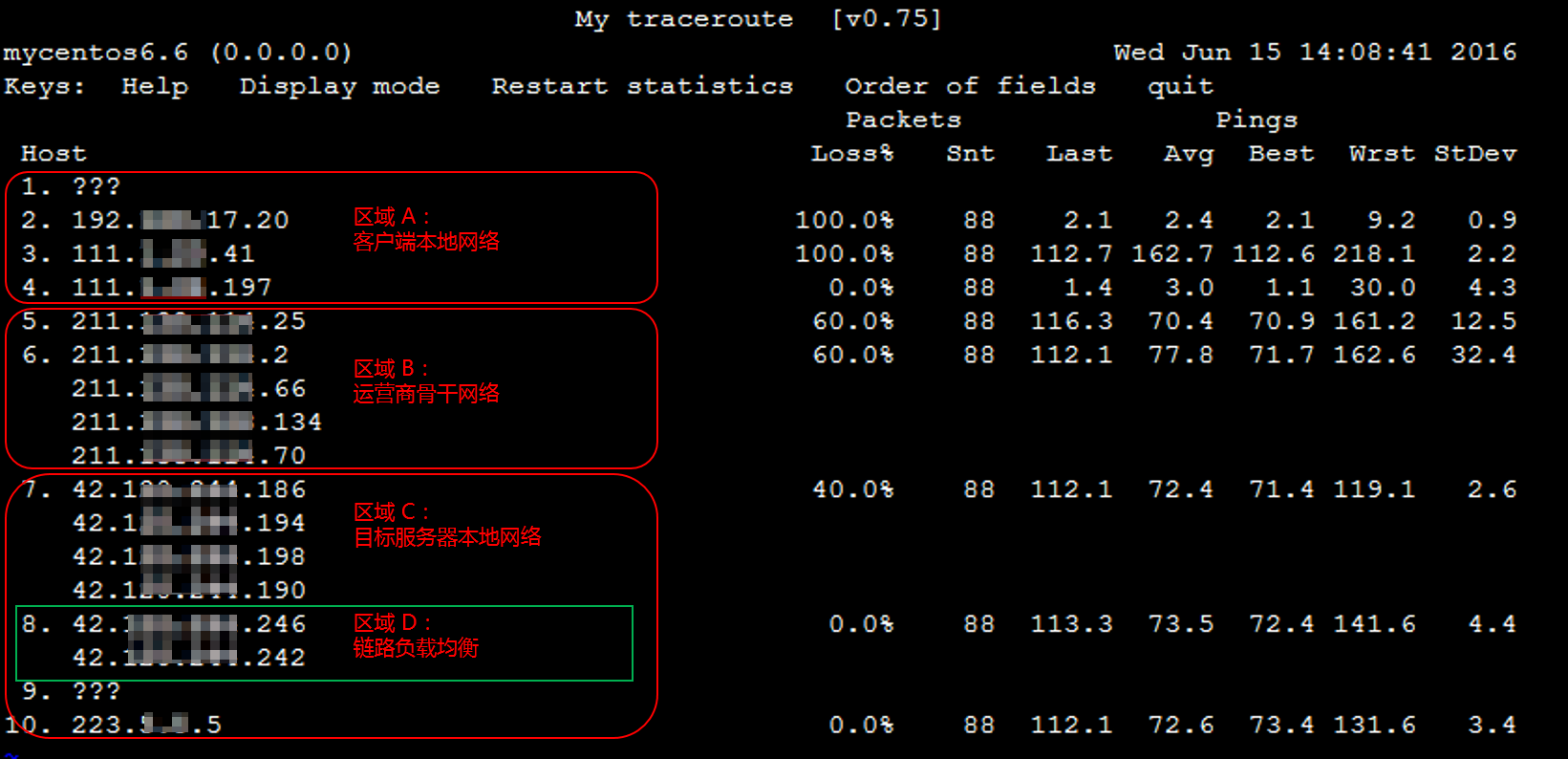
主要输出的信息如下:
HOST:节点的 IP 地址或域名。
Loss%:丢包率。
Snt:每秒发送的数量包的数量。
Last:最近一次的响应时间。
Avg:平均响应时间。
Best:最短的响应时间。
Wrst:最长的响应时间。
StDev:标准偏差,偏差值越高,说明各个数据包在该节点的响应时间相差越大。
报告结果分析及处理
说明:
由于网络状况的非对称性,遇到本地到服务器的网络问题时,建议您收集双向的 MTR 数据(从本地到云服务器以及云服务器到本地)。
1. 根据报告结果,查看目的服务器 IP 是否丢包。
如果目的地没有丢包,则表示网络正常。
如果目的地发生丢包,则执行 步骤2。
2. 往上查看报告结果,定位第一次丢包的节点。
如果丢包发生在目的服务器,则可能是目的服务器的网络配置不当引起,请检查目的服务器的防火墙配置。
如果丢包开始于前三跳,一般为本地运营商网络问题,建议检查访问其他网址是否存在相同情况。如果存在相同情况,请反馈给您的运营商进行处理。
如果丢包发生在接近目的服务器的几跳,则可能为目的服务器运营商的网络问题,请 提交工单 进行反馈处理。
提交工单时,请附上本地到目的服务器,以及目的服务器到本地的 MTR 测试截图,以便工程师进行定位。
Avg(平均值)和 StDev(标准偏差)
由于链路抖动或其他因素的影响,节点的Best和Wrst值可能相差很大;
Avg(平均值)统计了自链路测试以来所有探测的平均值,所以能更好的反应出相应节点的网络质量;
StDev越高,则说明数据包在相应节点的延时值越不相同(越离散):
如果StDev值很高,则同步观察相应节点的Best和Wrst,来判断相应节点是否存在异常。
如果StDev值不高,则通过Avg来判断相应节点是否存在异常
StDev值高或者不高,并没有具体的时间范围标准,而需要根据同一节点其他列的延迟值大小来进行评估。例如,如果Avg为30ms,当StDev为25ms时,则认为是很高的偏差。而如果Avg为325ms,当StDev同样为25ms时,反而认为是不高的偏差
Loss%(丢包率):
任一节点的Loss%(丢包率)如果不为零,则说明这一跳网络可能存在问题。导致相应节点丢包的原因通常有如下两种:
> 运营商基于安全或性能需求,人为限制了节点的ICMP发送速率,导致丢包。
> 节点确实存在异常,导致丢包。
> 您可以结合异常节点及其后续节点的丢包情况,来判定丢包原因:
> 如果随后节点均没有丢包,则通常说明异常节点丢包是由于运营商策略限制所致。可以忽略相关丢包。如前文链路测试结果示例图中的第2跳所示。
> 如果随后节点也出现丢包,则通常说明异常节点确实存在网络异常,导致丢包。如前文链路测试结果示例图中的第5跳所示。
> 如果随后节点出现没有丢包的节点和丢包的节点,即相应节点既存在策略限速,又存在网络异常。对于这种情况,如果异常节点及其后续节点连续出现丢包,而且各节点的丢包率不同,则通常以最后几跳的丢包率为准。如前文链路测试结果示例图所示,在第 5、6、7跳均出现了丢包。所以,最终丢包情况,以第7跳的40%作为参考
情景1: 在 mtr 中,出现“卡在第 5 个路由,一直显示 waiting for reply,没有继续往下走”的情况,可能有几种原因
- 防火墙或路由器策略阻止 ICMP 包
19. su
1
2
3
4
5
6
7
8
9
10
11
su: 全称:switch user,切换用户
su - USERNAME 切换用户后,同时切换到新用户的工作环境中
su USERNAME 切换用户后,不改变原用户的工作目录,及其他环境变量目录。
切换root
su - : 默认转换成root用户。类似: su -root 或 su -,su root
su : 不会改变当前工作目录以及HOME,SHELL,USER,LOGNAME。只是拥有了root的权限
20. uname
1
2
3
4
5
6
7
8
9
查看系统框架
x86_64,x64,AMD64基本上是同一个东西
arm是一个东西
uname -m
或
uname -a
arch
21. sftp
1
2
3
4
5
6
7
# 下载文件(不指定后面的 本地文件夹 也行)
get -r 远程服务器路径/文件夹 本地文件夹
get 远程服务器路径/文件 本地文件
# 上传文件(不指定后面的 远程服务器路径/文件(夹) 也行)
put -r 本地文件夹 远程服务器路径/文件夹
put 本地文件 远程服务器路径/文件
22. pstack
1
2
# 显示每个进程的栈跟踪
pstack pid
23. strace
1
2
3
4
5
6
7
8
9
10
11
12
13
14
strace -f -p 31636
strace -tt -T -v -f -e trace=file -o /data/log/strace.log -s 1024 -p 23489
-tt 在每行输出的前面,显示毫秒级别的时间
-T 显示每次系统调用所花费的时间
-v 对于某些相关调用,把完整的环境变量,文件stat结构等打出来。
-f 跟踪目标进程,以及目标进程创建的所有子进程
-e 控制要跟踪的事件和跟踪行为,比如指定要跟踪的系统调用名称
-e trace=file: 输出只显示和文件访问有关的内容
-o 把strace的输出单独写到指定的文件
-s 当系统调用的某个参数是字符串时,最多输出指定长度的内容,默认是32个字节
-p 指定要跟踪的进程pid, 要同时跟踪多个pid, 重复多次-p选项即可。
24. ps
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
找出僵尸进程
ps -A -ostat,ppid,pid,cmd | grep -e '^[Zz]'
命令将显示系统中所有进程的详细信息,包括它们的环境变量
ps -ef e
-e:显示所有进程,而不仅仅是当前终端下的进程
-f(全格式):以全格式(详细)输出显示进程信息。
全格式输出包括了进程的
UID(用户 ID)
PID(进程 ID)
PPID(父进程 ID)、
C(CPU 使用率)、
STIME(进程启动时间)等详细信息
e:这个选项告诉 ps 命令显示每个进程的环境变量,查看进程的环境变量或调试进程很有帮助
查看按 CPU 使用率倒序排列的进程,并显示前 10 个
1. 常用
ps aux --sort=-%cpu | head -n 10
2. 只想查看特定的字段,使用 awk 进行进一步过滤
ps aux --sort=-%cpu | awk 'NR==1 || NR<=10 {print $1, $2, $3, $4, $11}'
ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
ljw 146272 1005 0.2 61454612 2189664 ? Dl 6月19 69475:39 python main_process.py
USER: 运行进程的用户。
PID: 进程 ID。
%CPU: 进程使用的 CPU 时间百分比。对于多核系统,这个值可以超过 100%。例如,如果一个进程使用了两个 CPU 核心的全部时间,它的 %CPU 值可能为 200%。
%MEM: 进程使用的物理内存百分比。
VSZ: 进程使用的虚拟内存大小(以 KB 为单位)。
RSS: 进程使用的常驻内存大小(以 KB 为单位)。
TTY: 进程所属的终端。如果与终端无关,则显示 ?。
STAT: 进程状态码。常见的状态码包括:
R: 运行(running)
S: 休眠(sleeping)
D: 不可中断的睡眠(uninterruptible sleep)
Z: 僵尸进程(zombie)
T: 停止(stopped)
I: 空闲(idle)
START: 进程启动时间。
TIME: 进程使用的总 CPU 时间。
COMMAND: 启动进程的命令。
25. bc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
bc命令可以设置结果的位数,通过 scale
echo "scale=4; 1.2323293128 / 1.1" | bc -l
1.1202
scale只对除法、取余、乘幂有效,比如乘法就无效
echo "scale=4; 1.2323293128 * 1.1" | bc -l
1.3555622440
想要实现 除以 1
echo "scale=4; (1.2323293128 * 1.1) / 1" | bc -l
1.3555
bc显示小数点前的0
echo "scale=2; a=1/3; if (length(a)==scale(a)) print 0;print a "|bc
0.33
26. scp
1
2
scp拷贝带端口
scp -P port srcfile username@address:destpath
27. tar
1
2
打包隐藏文件
tar -zcvf xxx.tar.gz `ls -A`
28. tr
1
2
3
4
5
去除空行
cat qqq | tr -s "\n"
替换回车: 替换为 |
tr "\n" "|"
29. traceroute
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
traceroute 147.182.236.83
traceroute to 147.182.236.83 (147.182.236.83), 64 hops max, 52 byte packets
1 192.168.3.1 (192.168.3.1) 6.155 ms 1.442 ms 3.752 ms
2 (117.143.223.21) 15.887 ms 6.447 ms 4.915 ms
3 (117.135.49.77) 5.140 ms
(117.135.49.53) 5.235 ms
(117.135.49.77) 5.347 ms
4 (221.181.125.82) 6.635 ms
(221.181.125.102) 5.863 ms
(221.181.125.82) 5.823 ms
5 111.24.3.117 (111.24.3.117) 7.417 ms 11.469 ms
111.24.4.105 (111.24.4.105) 6.579 ms
6 221.183.89.41 (221.183.89.41) 9.385 ms
221.183.89.1 (221.183.89.1) 8.636 ms
221.183.89.41 (221.183.89.41) 9.058 ms
7 221.183.89.70 (221.183.89.70) 6.660 ms
221.176.22.30 (221.176.22.30) 6.622 ms
221.183.89.34 (221.183.89.34) 11.087 ms
8 221.183.89.177 (221.183.89.177) 8.048 ms
221.183.25.194 (221.183.25.194) 51.250 ms
221.183.89.177 (221.183.89.177) 7.234 ms
9 221.183.55.29 (221.183.55.29) 6.408 ms
221.183.55.49 (221.183.55.49) 7.244 ms
223.120.22.54 (223.120.22.54) 12.220 ms
10 223.120.12.149 (223.120.12.149) 191.609 ms
223.120.6.54 (223.120.6.54) 190.047 ms
223.120.12.149 (223.120.12.149) 193.304 ms
11 ae-17.edge6.seattle1.level3.net (4.68.39.221) 195.373 ms
223.120.6.54 (223.120.6.54) 208.139 ms
223.120.22.14 (223.120.22.14) 46.492 ms
12 223.120.6.54 (223.120.6.54) 204.583 ms
ae-11-70.ear2.sanjose1.level3.net (4.69.202.241) 297.455 ms *
13 * 4.14.33.54 (4.14.33.54) 308.532 ms *
14 4.14.33.54 (4.14.33.54) 209.130 ms
138.197.246.18 (138.197.246.18) 288.177 ms
4.14.33.70 (4.14.33.70) 321.658 ms
15 * * 138.197.246.26 (138.197.246.26) 272.867 ms
16 * * *
17 138.197.246.24 (138.197.246.24) 235.713 ms * *
18 * * *
19 147.182.236.83 (147.182.236.83) 220.820 ms 210.355 ms 211.505 ms
30. vim
1
2
3
4
5
6
7
改写插入
c[n]w: 改写光标后1(n)个词。
c[n]l: 改写光标后n个字母。
c[n]h: 改写光标前n个字母。
[n]cc: 修改当前[n]行。
[n]s: 以输入的文本替代光标之后1(n)个字符,相当于c[n]l。
[n]S: 删除指定数目的行,并以所输入文本代替之。
31. iostat
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
-x 显示cpu、磁盘的详细信息
-c 只显示cpu信息
-d 只显示磁盘信息
-m 磁盘读写速率M/s
iostat -x -m 2 10 以 M/s 显示cpu、磁盘的信息, 2s一间隔,执行10次
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
$ iostat -x 1 10
Linux 5.4.0-74-generic (hostname) 06/20/2024 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
1.24 0.00 0.38 0.05 0.00 98.33
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
sda 1.25 2.50 100.00 200.00 0.05 1.00 3.00 28.00 5.00 6.00 0.50 80.00 40.00 1.00 3.75
Device: 设备名称。
r/s: 每秒完成的读请求数。
w/s: 每秒完成的写请求数。
rkB/s: 每秒读取的数据量(单位:KB)。
wkB/s: 每秒写入的数据量(单位:KB)。
rrqm/s: 每秒进行的读请求合并数。
wrqm/s: 每秒进行的写请求合并数。
%rrqm: 读请求合并的百分比,即 rrqm/s 占总读请求数的比例。
%wrqm: 写请求合并的百分比,即 wrqm/s 占总写请求数的比例。这通常是有利的,因为合并写请求可以减少磁盘的写操作次数,提高 I/O 性能
r_await: 读请求的平均等待时间(毫秒)。
w_await: 写请求的平均等待时间(毫秒)。
aqu-sz: 活动请求的平均队列长度。
rareq-sz: 读请求的平均大小(KB)。
wareq-sz: 写请求的平均大小(KB)。
svctm: 每次 I/O 操作的平均服务时间(毫秒)。
%util: 设备的利用率,表示设备有多大比例的时间在处理 I/O 请求。
32. tune2fs
1
2
3
4
5
6
功能: 可修改系统磁盘预留空间, Linux系统默认预留空间: 5%
-l : 查看磁盘信息
-m n : 修改对应磁盘预留空间为 n%
tune2fs -m 1 /dev/vda1 # 将 挂载的磁盘 /dev/vda1,系统预留空间修改为 1%
33. systemctl
1
2
3
4
5
systemctl --failed 查看启动失败的服务
systemctl reset-failed 清除所有失败的单元
systemctl status 查看服务的状态
systemctl list-units 查看当前所有服务的启动状态
systemctl list-unit-files 查看服务开机是启动状态(enable/disabled/static)
34. nslookup
1
2
3
4
5
nslookup baidu.com 获取域名域名记录
nslookup -type=mx baidu.com 指定域名查询的类型(例如,A、HINFO、PTR、NS、MX等)
nslookup baidu.com 223.5.5.5 指定DNS地址 查询baidu.com对应域名记录
35. ss
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
ss:
显示所有套接字或网络连接
Netid–套接字类型。常见的类型是
TCP
UDP
u_str(Unix流)
u_seq(Unix序列)
State–套接字的状态。常见状态为
ESTAB(已建立)
UNCONN(未连接)
LISTEN(正在侦听)
CLOSE-WAIT
SYN-SENT
36. tree
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
-a 打印所有文件,包括隐藏文件、目录
-C 在文件和目录清单上加上色彩,便于区分文件类型
-d 仅列出目录名称,而非内容
-D 列出文件或目录更改时间
-L 目录树的最大显示深度
-p 打印结构同时打印文件权限
-l 跟随目录的符号链接,就像它们是目录一样。 避免了导致递归循环的链接
-f 打印每个文件的完整路径前缀
-F 在每个条目后加上文件类型的指示符(如目录是/)
tree -F -L 2
├── data/
│ ├── dkim/
│ ├── domain-info/
│ ├── domain-info.txt
│ ├── domain-info.txt-20221130
│ ├── domain-info.txt-20221201
│ ├── domain-info.txt.default
│ ├── domain-info-wangyi.txt
│ ├── domain-info-wangyi.txt-20221201
│ ├── domain-mail.txt
│ ├── domain-orig.info
│ └── EwoMail/
├── logs/
│ ├── ewomail_install.err
│ └── ewomail_install.log
├── main.sh*
└── module/
├── create_dns_analysis.sh
├── get-dns-analysis.sh*
├── init_domain-info.sh
├── install-ewomail.sh*
├── installScript/
├── login-expect.exp
├── stop-amavisd.sh*
└── wangyi-transport.sh*
37. passwd
1
2
3
4
5
6
7
8
9
10
-d 删除密码
-l 锁定用户密码,无法被用户自行修改
-u 解开已锁定用户密码,允许用户自行修改
-e 密码立即过期,下次登陆强制修改密码
-k 设置只有在密码过期失效后,方能更新
-S 查询密码状态
passwd -l root 锁定root用户,
cat /etc/shadow
root:!:19436:0::::: #root冒号后面就会变为!
38. tcpdump
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
-i: 端口号, 是指定抓取网卡的名称或者数字编号;
-s: 设置捕获的数据包的最大字节大小。
默认情况下,TCPDUMP 只会捕获每个数据包的前 262144 字节;
设置捕获的数据包的最大字节大小为 0,表示捕获整个数据包,不进行截断
-n: 来关闭dns反向解析功能; 不解析主机名, 直接显示 IP 地址
-nn: 不解析端口名, 是关闭反向查询功能并以数字格式显示ip地址端口号,和url地址
不带这个选项回显会很慢
-c COUNT: 一旦捕获了指定数量的数据包,就停止
-C COUNT: 每个文件的大小限制为 N MB。达到这个大小时,创建一个新文件
-v, -vv, -vvv: 增加输出的详细程度。每增加一个 "v",输出的详细程度就增加一次
-w FILE: 将捕获的数据包写入文件
-W COUNT: 保留 N 个文件。超过 N 个文件时,覆盖最旧的文件
-e:显示数据链路层头部信息,例如 MAC 地址
host IP: 只显示与指定主机相关的数据包
注: 选项不带参数可以写在一起,如-nev
例如:
tcpdump -i eth0 -nnevv host 192.168.205.201
: 在 eth0 网络接口上捕获与主机 192.168.205.201 有关的数据包,显示其详细信息(包括数据链路层头部),并直接显示 IP 地址和端口号,而不进行名称解析
tcpdump -i eth0 -s 0 -w /tmp/1.pcap
: 在 eth0 网络接口上捕获数据包,并将捕获到的数据包写入到 /tmp/1.pcap; 会持续捕获数据包,直到你手动停止(如按 Ctrl+C)
tcpdump udp port 52421 -nn -vvv -s 0 -w /tmp/172-19-255-126.pcap
: 使用tcpdump工具来捕获 UDP 端口为52421的网络流量,并将捕获的数据保存到/tmp/172-19-255-126.pcap文件中
tcpdump -i eth0 -s 0 -W 10 -C 10 -w /tmp/1.pcap
在 eth0 接口上进行抓包,每个文件大小限制为 10 MB,最多保留 10 个文件。文件名会依次为 /tmp/1.pcap0, /tmp/1.pcap1, ..., /tmp/1.pcap9。当文件数量超过 10 个时,最旧的文件会被覆盖
39. date
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
%Y:显示四位数的年份(例如:2022)。
%y:显示两位数的年份(例如:22)。
%m:显示两位数的月份(01-12)。
%d:显示两位数的日期(01-31)。
%F:完整格式的日期,与%Y-%m-%d相同,例如2018-12-18
%H:显示24小时制的小时(00-23)。
%I:显示12小时制的小时(01-12)。
%M:显示两位数的分钟(00-59)。
%S:显示两位数的秒数(00-59)。
%N:显示纳秒级的时间(000000000-999999999)。
%T:等价: %H:%M:%S,时分秒
%p:显示AM或PM。
%Z:显示时区信息(例如:PST,EST)。
%A:显示完整的星期几名称(例如:Sunday)。
%a:显示缩写的星期几名称(例如:Sun)。
%B:显示完整的月份名称(例如:January)。
%b:显示缩写的月份名称(例如:Jan)。
%c:显示本地日期和时间的默认格式。
%s:显示从1970年1月1日00:00:00 UTC到现在的秒数(Unix时间戳)
#=========================================================================
# 虽然 %N 是纳秒, 但是毫秒计算方式是 %N/1000000, 即前三个数就是毫秒
显示当前时间包含毫妙: date +%H:%M:%S.%3N
#=========================================================================
# 时间戳与时间直接转换:
时间戳转换为时间:
date -d @1740972234
date -d @1740972234 +"%Y/%m/%d %H:%M:%S"
时间转换为时间戳:
date +%s
date -d "2025-03-03 10:27:22" +%s
#=========================================================================
# 时间偏移量
date +%Y%m%d --date="-1 day" # 显示前一天日期
"+"表示要晚与当前时间,“-”表示早与当前时间,具体偏移单位表示,如下:
year—>年
month—>月
day—>天
hour—>时
minute—>分
second—>秒
40. ping
1
2
3
4
5
6
7
8
9
10
11
12
13
14
-s:指定发送的数据包大小(字节)。
默认情况下,数据包大小通常是 56 字节,加上 ICMP 头部的 8 字节,总共是 64 字节。
-i:指定两次连续数据包之间的时间间隔(秒)。默认情况下,这个间隔是 1 秒。
-c:指定发送的数据包数量。默认情况下,ping 会持续发送数据包直到被中断。
-t:(仅限 macOS 和 BSD 系统)设置数据包的存活时间(TTL)。在 Linux 系统中,使用 -T 选项来设置 TTL。
eg:
ping -s 100 -i 2 -c 10 34.87.189.72
向 34.87.189.72 每隔2秒 发送10个 大小为 100字节的包
41. iperf3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
网络性能测试工具,用于测量带宽和延迟
-s: 以服务端模式运行
-B IP: 绑定特定的 IP 地址, 表示服务器将只在这个指定的 IP 地址上接受连接
-i num: 设置报告间隔,默认为 1 秒
-p: 监听的端口号,默认为5201
-c IP: 连接服务器,指定ip地址
-t num: 持续时间运行时间
启动服务:
iperf3 -s -B 10.200.0.11 -i 1 -p 6666
以本机IP为: 10.200.0.11的网卡启动6666的端口,报告间隔为 1 秒
客户端连接:
iperf3 -c 10.200.0.11 -B 10.200.0.12 -p 6666 -t 60 -i 1
以本机网卡IP为: 10.200.0.12 连接服务端: 10.200.0.11 的6666端口,并间隔1s发送60s的请求
42. touch
1
2
3
4
5
6
7
-t 时间戳: 修改创建时间(mac), 时间戳格式: 202207140100
-a 时间戳: 修改访问时间, 时间戳格式: 202207140100
touch -t 202203101840 <file>
eg:
touch -t 202203101840 /tmp/abc.txt
43. jq
1
2
3
4
-r: 返回值去除引号
# 解析json,获取指定的字段,并组装成一个单独的列表
jq -r '.data.info[] | [.bk_inst_name, .host_innatip]'
44. ctr
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
1. 列出容器
要列出当前正在运行的容器,你可以使用以下命令:
sudo ctr containers list
较新版本的 containerd,你可能需要指定命名空间
sudo ctr -n k8s.io containers list
: Kubernetes 通常会在 containerd 中使用 k8s.io 命名空间
2. 查看容器的详细信息
要查看特定容器的详细信息,你可以使用 ctr containers info 命令:
sudo ctr -n k8s.io containers info <container-id>
3. 查看容器日志
要查看容器的日志,你可以使用 ctr tasks logs 命令:
sudo ctr -n k8s.io tasks logs <container-id>
4. 拉镜像
ctr images pull <镜像名>
列出镜像:
ctr images ls
45. vmstst
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
vmstat 1 10
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 5537224 342032 1017307072 0 0 11 19 0 0 5 1 94 0 0
3 0 0 5536488 342032 1017307072 0 0 0 4 9372 16247 0 1 98 0 0
3 0 0 5536624 342032 1017307072 0 0 0 4 11377 20796 0 1 99 0 0
r: 运行队列中的进程数(即正在使用CPU或等待使用CPU的进程数)。
b: 等待I/O的进程数。
swpd: 使用的交换内存大小(单位:KB)。
free: 空闲的内存大小(单位:KB)。
buff: 用于缓冲的内存大小(单位:KB)。
cache: 用于缓存的内存大小(单位:KB)。
si: 每秒从磁盘交换到内存的交换页数(swap in,单位:KB)。
so: 每秒从内存交换到磁盘的交换页数(swap out,单位:KB)。
bi: 每秒读取的块数(块设备I/O)。
bo: 每秒写入的块数(块设备I/O)。
in: 每秒的中断次数。
cs: 每秒的上下文切换次数。
us: 用户态CPU时间百分比。
sy: 内核态CPU时间百分比。
id: 空闲CPU时间百分比。
wa: 等待I/O的CPU时间百分比。
st: 被虚拟机窃取的CPU时间百分比。
46. perl
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
广泛用于文本处理、系统管理、网络编程等。你提到的 Perl 命令用于对文件进行 正则表达式替换,并将结果写回文件
=============================================================================
-i: In-place Editing
该选项允许对文件进行就地编辑。它会将文件内容替换为脚本处理后的结果。使用 -i,文件的内容将被修改为替换后的内容,而不会输出到终端。如果你想保留备份,可以使用 -i.bak,它会为原始文件创建一个备份。
-p: Print Processing Loop
-p 选项会让 Perl 自动将每行数据读入到内置变量 $_ 中,并在处理完成后自动打印出来。因此,这个选项相当于隐含地将文件内容逐行进行处理,并将结果输出。
`-e '...': Inline Script Execution
-e 选项允许在命令行中直接书写 Perl 代码,而不需要将脚本保存在单独的文件中。脚本内容写在单引号或双引号内。
正则表达式: (s{pattern}{replacement})
正则表达式替换操作符。它的作用是用 替换内容 替换掉 匹配的模式
模式部分 ({pattern})
替换部分 ({replacement})
修饰符 (ge)
g: Global Matching
使得替换操作在每一行中全局执行,匹配所有符合模式的子串,而不仅仅是第一个。
e: Evaluate Replacement as Code
这个修饰符告诉 Perl 将替换部分视为代码并执行,而不仅仅是一个普通的字符串。这里用于对捕获的内容进行操作(例如拼接路径、转换为小写等)
=============================================================================
eg:
perl -i -pe 's{\[\[([^\/]*)\/(.*?)(#(.*?))?\|(.*?)\]\]}{"[$5](../" . (join "-", split "/", $2) . ($4 ? "#" . (join "666", split "\\\\", (join "-", split ". ", $4)) : "") . ")"}ge' ${filepath}
匹配部分:
\[\[([^\/]*)\/(.*?)(#(.*?))?\|(.*?)\]\]:
\[\[: 匹配字符串的开头 [[。
([^\/]*): 捕获第一个部分,直到遇到 /,捕获到的是第一个部分(可能是名称、ID 等)。
\/: 匹配斜杠 /。
(.*?): 捕获所有字符,直到遇到 |。这个捕获组可能是路径或其他信息。
(#(.*?))?: 可选的哈希部分,捕获 # 后面的内容。
\|: 匹配 | 字符。
(.*?): 捕获所有字符,直到 ]],通常是链接文本。
\]\]: 匹配字符串的结尾 ]]。
替换部分:
"[$5](../" . (join "-", split "/", $2) . ($4 ? "#" . (join "666", split "\\\\", join "-", split ". ", $4)) : "") . ")"
[$5]: 将匹配的第 5 个捕获组(链接文本)作为 Markdown 格式的链接文本 [Link Text]。
(../" . (join "-", split "/", $2)):
split "/", $2: 将第二个捕获组按 / 进行分割,生成一个列表。
join "-", ...: 使用 - 连接分割后的路径片段。
../: 在路径前添加 ../,相当于将路径转换为相对路径。
例如,如果 $2 是 "path/to/resource",它将转换为 "../path-to-resource"。
($4 ? "#" . (join "666", split "\\\\", (join "-", split ". ", $4)) : ""):
检查是否存在哈希部分(即 $4 是否存在)。
如果存在:
split "\\\\", (join "-", split ". ", $4): 先将 $4 按 "." 分割,然后将分割结果按 "-" 重新连接,最后再按 "\\\\" 进行分割。
join "666", ...: 用 "666" 将分割后的内容连接起来。
拼接结果为哈希部分(# 开头)。
如果 $4 不存在,替换为空字符串。
比如:
[My Link](../path-to-resource#section)
$5 = "My Link"
$2 = "path/to/resource" → 转换为 "path-to-resource"
$4 = "section" → 转换为 "#section"
替换为: [My Link](../path-to-resource#section)
47. base64
1
2
3
4
5
6
7
8
9
10
11
12
13
# 加密
echo "xxxx" | base64
base64 -w 0 filename.txt
# base64加密,默认规则 按照每行 76 个字符自动添加回车符,需要去掉
echo "需要加密的内容" | base64 | tr -d '\n'
或
echo "需要加密的内容" | base64 -w 0 # 部分系统不支持 -w 参数
# 解密
echo "需要解密的内容" | base64 -d
本文由作者按照
CC BY 4.0
进行授权