K8s概念相关
k8s基础概念
1. k8s: 连接众多计算机成为集群资源池
1
2
3
4
5
6
7
8
9
10
11
12
13
14
涉及名词概念
etcd: 读写信息的存储, 所有的信息都存储在这,保存了整个集群的状态;持久化
apiserver: 提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
controller manager: 负责维护集群的状态,维持副本期望数目,比如故障检测、自动扩展、滚动更新等;
scheduler: 负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;
kubelet: 负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理;
Container runtime: 负责镜像管理以及Pod和容器的真正运行(CRI);
kube-proxy: 负责为Service提供cluster内部的服务发现和负载均衡; 是一个分布式代理服务器,在K8s的每个节点上都有一个
2. 学习k8s各部分需要掌握的东西
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Pod控制器: 掌握各种控制器的特点以及使用定义方式;
服务发现: 掌握 SVC 原理及其构建方式;
存储: 掌握多种存储类型的特点, 并且能够在不同环境中选择合适的存储方案(有自己的见解)
调度器: 掌握调度器的原理, 能根据要求把Pod定义到想要的节点运行
安全: 集群的认证、鉴权、访问控制 原理及其流程
HELM: Linux yum 掌握 HELM 原理 HELM 面板自定义、部署一些常用软件
运维: 修改 kubeadm 可用证书期限修改为10年甚至更高
服务分类: 有状态服务: DBMS
无状态服务: LVS APACHE
3. deployment启动pod
用户通过 kubectl 创建 Deployment。
Deployment 创建 ReplicaSet。
ReplicaSet 创建 Pod
详细过程
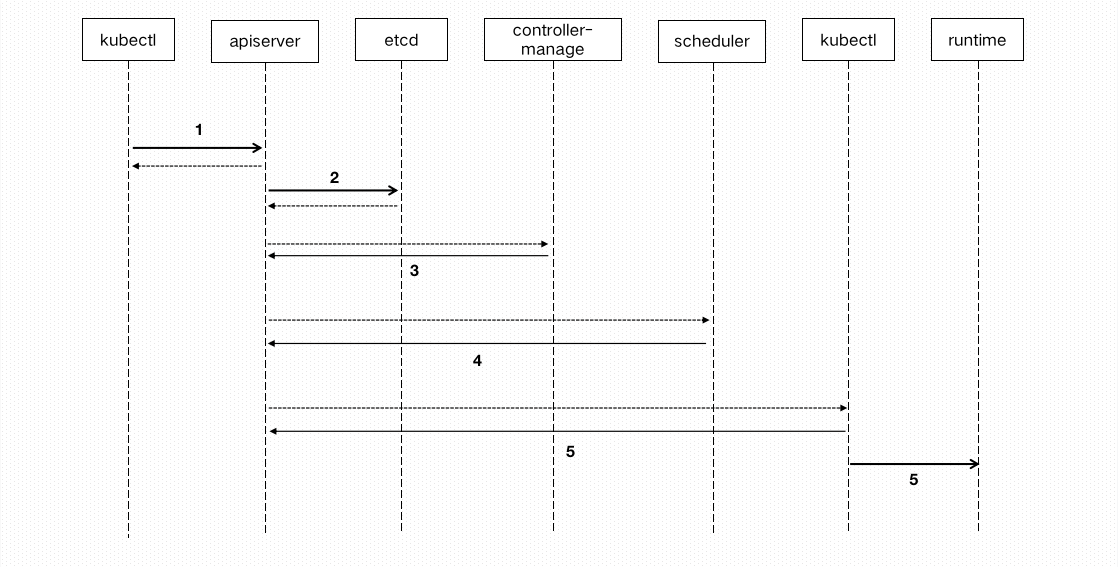
1. kubectl 向 apiserver 发送部署请求(例如使用 kubectl create -f deployment.yml)
2. apiserver 将 Deployment 持久化到 etcd;etcd 与 apiserver 进行一次http通信。
3. controller manager 通过 watch api 监听 apiserver ,deployment controller看到了一个新创建的 deplayment对象 更后,将其从队列中拉出,根据deployment 的描述 创建一个ReplicaSet,并将 ReplicaSet 对象返回apiserver并持久化回etcd。以此类推,当replicaset控制器看到新创建的replicaset对象,将其从队列中拉出,根据描述创建pod对象。
4. 接着 scheduler 调度器看到未调度的pod对象,根据调度规则选择一个可调度的节点,加载到pod描述中nodeName字段,并将pod对象返回 apiserver 并写入 etcd。
5. kubelet 在看到有 pod对象 中 nodeName 字段属于本节点,将其从队列中拉出,通过容器运行时创建 pod 中描述的容器。

4. ReplicaSet控制pod
1
确保容器应用的副本数始终保持在用户定义的副本数
5. k8s中各类控制器的关系
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
控制器的选择取决于应用程序的需求和管理模式。
只有需要管理 Pod 副本的控制器(如 Deployment 和 StatefulSet)会依赖 ReplicaSet。其他控制器如 DaemonSet 和 Job 则独立管理 Pods。
各类控制器与ReplicaSet控制器的关系:
==========================================================================
1. Deployment
依赖关系: Deployment 控制器直接使用 ReplicaSet 来管理 Pods。每次更新或扩展时,Deployment 会创建新的 ReplicaSet。
2. StatefulSet
依赖关系: StatefulSet 使用 ReplicaSet 来管理有状态的 Pods,但提供了有序性和持久性的保证。
3. DaemonSet
依赖关系: DaemonSet 控制器不使用 ReplicaSet。它确保每个节点(或选定的节点)运行一个 Pod 实例,适用于日志收集、监控等场景。
4. Job 和 CronJob
依赖关系: Job 和 CronJob 控制器也不依赖于 ReplicaSet。它们用于批处理任务,确保 Pods 完成特定工作。
5. ReplicationController
依赖关系: ReplicationController 是 ReplicaSet 的前身,管理无状态 Pods,但现在更推荐使用 ReplicaSet。
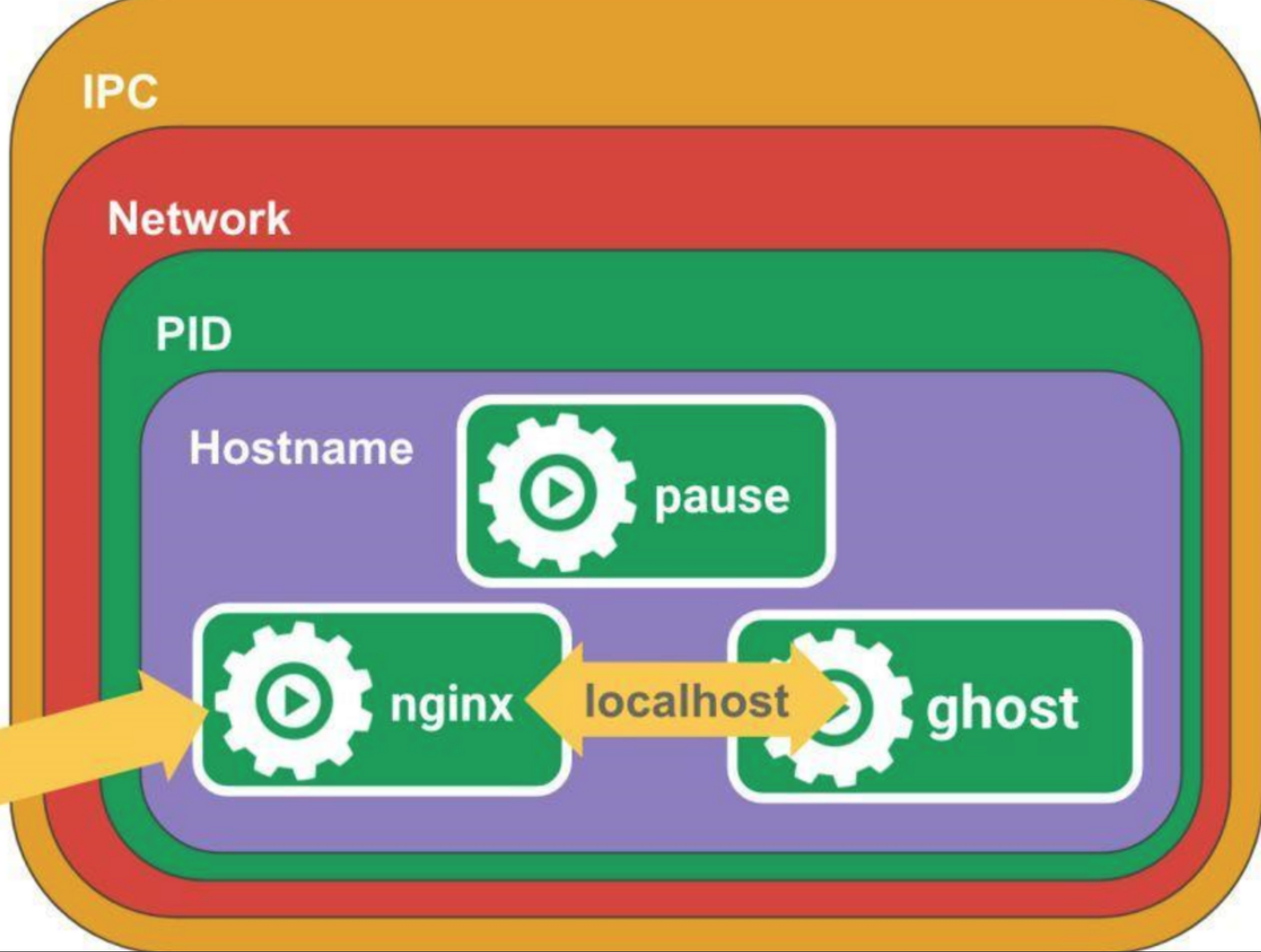
6. pause容器作用
pause容器主要为每个业务容器提供以下功能:
① PID命名空间:Pod中的不同应用程序可以看到其他应用程序的进程ID。
② 网络命名空间:Pod中的多个容器能够访问同一个IP和端口范围。
③ IPC命名空间:Pod中的多个容器能够使用SystemV IPC或POSIX消息队列进行通信。
④ UTS命名空间:Pod中的多个容器共享一个主机名;Volumes(共享存储卷):
⑤ Pod中的各个容器可以访问在Pod级别定义的Volumes。
pause容器 主要为每个业务容器提供以下功能: 在pod中担任Linux命名空间共享的基础
k8s-pv-持久化-持久访问模式
1. ReadOnlyMany – 卷可以被许多节点以只读方式挂载
1
2
3
4
5
6
7
如果一个 pod 挂载了一个 ReadOnlyMany 访问模式的卷,其他 pod 可以挂载它并且只执行读取操作。现在 GCP 不支持这种方法。
这意味着卷可以挂载在 Kubernetes 集群的一个或多个节点上,并且您只能执行读取操作。
您有一个 Pod 在节点上运行,并且您正在从卷中读取存储的文件。在同一卷上,您无法执行写入操作。
由于它是 ReadOnlyMany,如果您的 pod 被调度到另一个节点,那么卷和数据也将可用于执行读取操作。
2. ReadWriteMany – 卷可以被许多节点以读写方式挂载
1
2
3
4
5
6
7
如果一个 pod 挂载了一个 ReadWriteMany 访问方式的卷,其他 pod 也可以挂载它。
这意味着卷可以挂载在 kubernetes 集群的一个或多个节点上,您可以同时执行读写操作。
您在一个节点上运行了一个 pod,并且您正在从卷中读取和写入存储的文件。
由于它是 ReadWriteMany,如果您的 pod 调度到另一个节点,那么卷和数据也将在那里可用以执行读/写操作。
3. ReadWriteOnce – 卷可以由单个节点以读写方式挂载
1
2
3
4
5
6
7
如果 pod 以 ReadWriteOnce 访问模式挂载卷,则其他 pod 无法挂载它。在 GCE (Google Compute Engine) 中,唯一允许的模式是 ReadWriteOnce 和 ReadOnlyMany。因此,要么一个 pod 挂载 ReadWrite 卷,要么一个或多个 pod 挂载 ReadOnlyMany 卷。
这意味着卷可以挂载在onlykubernetes 集群的一个节点上,并且您只能执行读取操作。
您在节点上运行了一个 pod,并且您正在从卷中读取存储的文件。在同一卷上时,您无法执行写入。
因为它是 ReadWriteOnce 如果您的 pod 被安排到另一个节点,那么可能 mossible 卷将附加到该节点并且您无法访问那里的数据。
Pod指标WSS和RSS区别
1. WSS(Working Set Size)
- 定义:
- WSS 是指 Pod 当前正在使用的内存量,包括活跃的、最近被访问的和缓存的内存。它代表了应用程序实际需要的内存量。
- 特点:
- WSS 是动态变化的,随着应用程序的运行状态而变化。
- 它更能反映应用程序的实时内存需求,因此对资源调度和优化非常重要。
- WSS 不包括被操作系统回收或未被使用的内存。
2. RSS(Resident Set Size)
- 定义:
- RSS 是指进程占用的物理内存量,不包括被交换出去的部分。它是指进程在内存中实际驻留的部分,包括代码、数据和堆栈。
- 特点:
- RSS 是相对静态的,通常在进程运行期间变化较小。
- 它包括所有分配的内存,无论是否被使用。
- RSS 可以帮助识别内存泄漏,因为如果 RSS 不断增加而 WSS 稳定,可能意味着有不再使用的内存仍然被保留。
3. 总结
- WSS:反映应用程序当前的实际内存需求,动态变化,更关注活跃和近期使用的内存。
- RSS:表示进程在物理内存中占用的总量,包括所有分配的内存,适合监控内存使用的整体情况。
了解这两个指标的区别有助于更好地进行资源管理和优化。监控 WSS 和 RSS 可以帮助识别性能瓶颈、内存泄漏等问题,从而更有效地调度和配置 Kubernetes 集群中的资源。
健康检查(探针)
共有三类探针:存活、就绪和启动探针
当服务出现问题,进程却没有退出,如系统超载 5xx 错误,资源死锁等,就需要健康检查机制出场了
存活探针
存活探针(Liveness probe):让Kubernetes知道你的应用程序是否健康,如果你的应用程序不健康,Kubernetes将启动一个新的替换它。这里的“健康”不再是进程状态,而是用户自定义探测方式:HTTP、TCP、Exec
就绪探针
就绪探针(Readiness probe):让Kubernetes知道您的应用是否准备好其流量服务。
Kubernetes确保Readiness探针检测通过,然后允许服务将流量发送到Pod。
如果Readiness探针开始失败,Kubernetes将停止向该容器发送流量,直到它通过。
判断容器是否处于可用Ready状态, 达到Ready状态表示Pod可以接受请求, 如果不健康, 从service的后端endpoint列表中把Pod隔离出去。
启动探针
对于慢启动容器来说,存活探针和就绪探针这两种健康检查机制不太好用
慢启动容器:指需要大量时间(一到几分钟)启动的容器。启动缓慢的原因可能有多种:
长时间的数据初始化:只有第一次启动会花费很多时间。
负载很高:每次启动都花费很多时间。
节点资源不足/过载:即容器启动时间取决于外部因素。
startupProbe 并不是一种新的数据结构,他完全复用了livenessProbe,只是名字改了下,多了一种概念。
注意:
- 启动探针只在容器启动期间起作用,一旦容器成功启动,存活探针和就绪探针将持续定期监控容器的健康状态,以保证容器的可用性和就绪状态;
- k8s 1.16 才开始支持;
Probe字段解析
| 字段名称 | 释义 | 备注 | | —————————– | ————————————————————————————- | ————————- | | initialDelaySeconds | 容器启动后要等待多少秒后才启动探针 | 默认是 0 秒,最小值是 0。 | | periodSeconds | 执行探测的时间间隔(单位是秒) | 默认是 10 秒。最小值是 1 | | timeoutSeconds | 探测的超时后等待多少秒。 | 默认值是 1 秒。最小值是 1 | | successThreshold | 探针在失败后,被视为成功的最小连续成功数 | 默认值是1。最小值是1 | | failureThreshold | 探针连续失败次数 | 默认值是3,最小值是1 | | terminationGracePeriodSeconds | 为 kubelet 配置从为失败的容器触发终止操作到强制容器运行时停止该容器之前等待的宽限时长 | 默认值是继承 Pod 级别的 terminationGracePeriodSeconds 值(如果不设置则为 30 秒),最小值为 1 |
注意:
如果就绪态探针的实现不正确,可能会导致容器中进程的数量不断上升。 如果不对其采取措施,很可能导致资源枯竭的状况。
HTTP 探测
1.HTTP Probes 允许针对 httpGet 配置额外的字段:
- host:连接使用的主机名,默认是 Pod 的 IP。也可以在 HTTP 头中设置 “Host” 来代替。
- scheme:用于设置连接主机的方式(HTTP 还是 HTTPS)。默认是 “HTTP”。
- path:访问 HTTP 服务的路径。默认值为 “/”。
- httpHeaders:请求中自定义的 HTTP 头。HTTP 头字段允许重复。
- port:访问容器的端口号或者端口名。如果数字必须在 1~65535 之间。
对于 HTTP 探测,kubelet 发送一个 HTTP 请求到指定的端口和路径来执行检测。
除非 httpGet 中的 host 字段设置了,否则 kubelet 默认是给 Pod 的 IP 地址发送探测。
如果 scheme 字段设置为了 HTTPS,kubelet 会跳过证书验证发送 HTTPS 请求。 大多数情况下,不需要设置 host 字段。
这里有个需要设置 host 字段的场景,假设容器监听 127.0.0.1,并且 Pod 的 hostNetwork 字段设置为了 true。那么 httpGet 中的 host 字段应该设置为 127.0.0.1。 可能更常见的情况是如果 Pod 依赖虚拟主机,你不应该设置 host 字段,而是应该在 httpHeaders 中设置 Host。